
Crawler und ihre Rolle beim Suchmaschinen-Ranking
Crawler sammeln Daten und Informationen aus dem Internet, indem sie Websites besuchen und die Seiten lesen. Erfahren Sie mehr über sie.
5 Min. Lesezeit
SEO
Crawlers
+4
Erfahren Sie, was der Google Spider (Googlebot) ist, wie er Websites crawlt und indexiert und warum er für SEO unerlässlich ist. Entdecken Sie, wie Sie Ihre Website für ein besseres Crawling optimieren.
Der Google Spider, formell als Googlebot bekannt, ist ein automatisiertes Programm, das Websites crawlt, um Inhalte zu entdecken, zu indexieren und in der Google-Datenbank zu speichern. Er folgt Links, um neue oder aktualisierte Seiten zu finden, die dann verarbeitet und dem Google-Suchindex hinzugefügt werden, wodurch die Suchmaschine relevante Ergebnisse für Nutzer bereitstellen kann.
Der Google Spider, formeller bekannt als Googlebot, ist ein automatisiertes Softwareprogramm, das systematisch das Internet durchsucht, um Webinhalte zu entdecken, zu analysieren und zu indexieren. Er ist das wichtigste Werkzeug, das Google verwendet, um Websites zu erkunden, Informationen zu sammeln und seinen riesigen Suchindex aufzubauen. Ohne den Googlebot wäre Google nicht in der Lage, neue Seiten zu entdecken, Aktualisierungen bestehender Inhalte zu erkennen oder Milliarden von Nutzern weltweit relevante Suchergebnisse zu liefern. Der Spider arbeitet kontinuierlich und besucht täglich Millionen von Websites, um sicherzustellen, dass der Google-Index aktuell und umfassend bleibt.
Googlebot ist im Wesentlichen ein ausgefeilter Webcrawler, der einem komplexen algorithmischen Prozess folgt, um zu bestimmen, welche Seiten besucht werden, wie häufig sie gecrawlt werden und wie viele Seiten von jeder Domain abgerufen werden. Der Crawler liest den HTML-Code, den Textinhalt und die Metadaten jeder besuchten Seite und speichert diese Informationen in der zentralen Google-Datenbank. Dieser Indexierungsprozess ist grundlegend für die Funktionsweise von Suchmaschinen und hat direkten Einfluss auf die Sichtbarkeit Ihrer Website in den Suchergebnissen.
Der Google Spider arbeitet nach einem klar definierten Crawling-Prozess, der mit einer Startliste bekannter Webseiten beginnt. Diese anfängliche Liste wird aus vorherigen Crawl-Prozessen generiert und kontinuierlich mit Sitemaps, die von Webmastern über die Google Search Console bereitgestellt werden, ergänzt. Wenn Googlebot eine Website besucht, liest er nicht nur den Inhalt – er analysiert die Seitenstruktur umfassend, folgt internen und externen Links und erkennt Veränderungen oder neue Inhalte, die seit dem letzten Besuch hinzugefügt wurden.
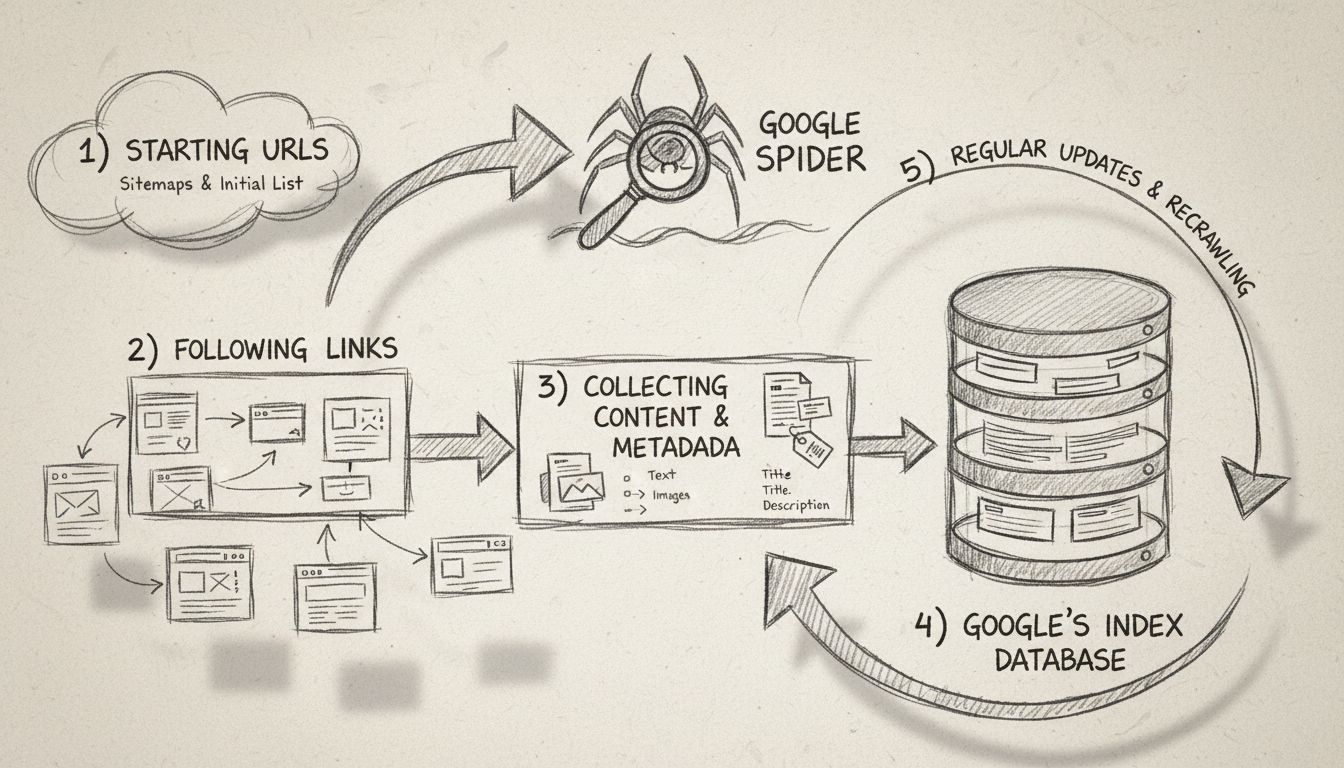
Der Crawling-Prozess folgt diesen Schritten: Zuerst startet Googlebot mit einer Liste von Webseiten-URLs aus früheren Crawls und Sitemaps. Zweitens navigiert er durch Websites, indem er Links (sowohl SRC- als auch HREF-Attribute) auf jeder Seite folgt, um neue Inhalte zu entdecken. Drittens ruft der Crawler den Inhalt jeder Seite ab und analysiert ihn, einschließlich Text, HTML-Struktur, Metadaten und anderer relevanter Informationen. Viertens werden diese gesammelten Daten an die Google-Server zur Verarbeitung und Speicherung im Suchindex gesendet. Schließlich besucht Googlebot Websites in regelmäßigen Abständen erneut, um nach neuen Inhalten, Aktualisierungen oder Änderungen an bestehenden Seiten zu suchen.
Richten Sie erweitertes Tracking in wenigen Minuten ein. Keine Kreditkarte erforderlich.
Google betreibt mehrere spezialisierte Crawler-Varianten, die jeweils für bestimmte Zwecke entwickelt und durch eindeutige User-Agent-Strings identifiziert werden. Das Verständnis dieser verschiedenen Typen hilft Website-Betreibern, ihre Seiten für den jeweiligen Crawler zu optimieren. Die wichtigsten Googlebot-Varianten sind der Desktop-Crawler, der Mobile-Crawler, der Video-Crawler, der Image-Crawler und der News-Crawler, die jeweils unterschiedliche Funktionen im Google-Indexierungs-Ökosystem erfüllen.
| Googlebot-Typ | User-Agent-String | Zweck |
|---|---|---|
| Googlebot (Desktop) | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) | Crawlt Desktop-Versionen von Websites für den allgemeinen Suchindex |
| Googlebot (Mobile) | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/W.X.Y.Z Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) | Crawlt mobil-optimierte Versionen von Websites |
| Googlebot-Video | Googlebot-Video/1.0 | Indexiert Videoinhalte, die auf Webseiten eingebettet sind |
| Googlebot-Image | Googlebot-Image/1.0 | Crawlt und indexiert Bilder für die Google Bildersuche |
| Googlebot-News | Googlebot-News | Crawlt Nachrichteninhalte für die Google News-Aggregation |
Über diese Hauptcrawler hinaus betreibt Google auch spezialisierte Bots für andere Zwecke. Der AdSense-Bot prüft die Anzeigenqualität und -konformität, während der Mobile Apps Android Crawler Inhalte aus Android-Anwendungen indexiert. Jeder Bot verfügt über einen eindeutigen User-Agent-Identifier, mit dem Website-Administratoren in Server-Logs verfolgen können, welcher spezifische Crawler auf ihre Seite zugreift. Diese Unterscheidung ist wichtig, da verschiedene Crawler unterschiedliche Crawl-Budgets und Prioritäten haben können, was beeinflusst, wie häufig sie Ihre Seite besuchen.
Der Google Spider ist absolut entscheidend für die Suchmaschinenoptimierung, da er bestimmt, ob die Inhalte Ihrer Website entdeckt, indexiert und in den Suchergebnissen gelistet werden. Wenn Googlebot Ihre Seite nicht effektiv crawlen kann, erscheinen Ihre Seiten nicht im Google-Index und sind für potenzielle Besucher, die nach Ihren Produkten oder Dienstleistungen suchen, unsichtbar. Aus diesem Grund ist technisches SEO – die Sicherstellung, dass Ihre Seite crawlerfreundlich ist – eine der wichtigsten Grundlagen jeder erfolgreichen SEO-Strategie.
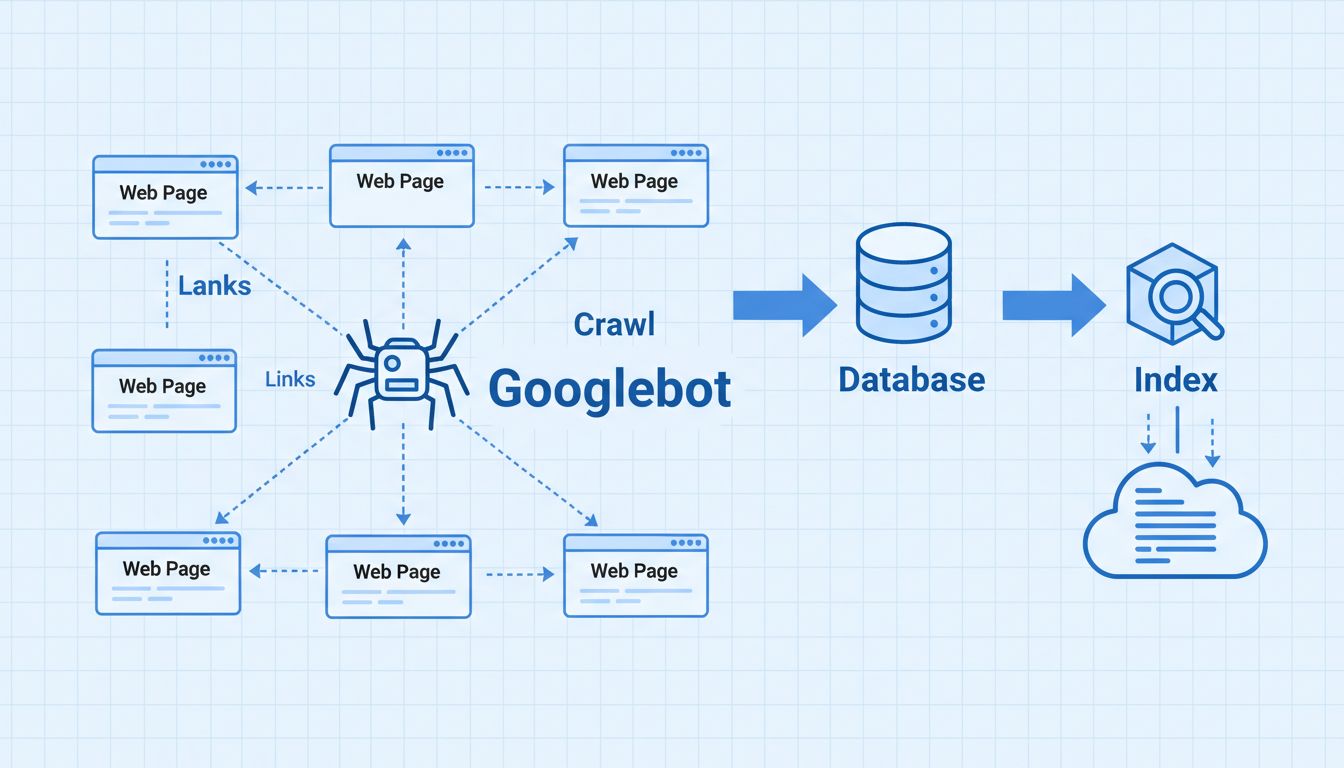
Wenn Googlebot Ihre Website crawlt, erstellt er einen umfangreichen Index aller gefundenen Wörter und deren Positionen auf jeder Seite sowie HTML-Informationen wie Title-Tags, Meta-Beschreibungen und Überschriftenstrukturen. Diese indexierten Informationen werden in der Google-Datenbank gespeichert und von Suchalgorithmen verwendet, um Seiten zu ranken und zu bestimmen, wie wertvoll Ihre Inhalte für bestimmte Suchanfragen sind. Je effizienter Googlebot Ihre Seite crawlen kann, desto häufiger kehrt er zurück und desto schneller werden neue Inhalte indexiert und potenziell in den Suchergebnissen gelistet.
Erfahren Sie als Erster von neuen Funktionen und Produkt-Updates.
Um sicherzustellen, dass Googlebot Ihre Website effektiv und effizient crawlen kann, sollten Sie mehrere technische Best Practices umsetzen. Pflegen Sie zunächst eine klare und logische Seitenstruktur mit einer ordentlichen Navigation, die es dem Crawler erleichtert, alle wichtigen Seiten zu entdecken. Interne Verlinkungen sollten strategisch und relevant platziert werden, wobei beschreibende Ankertexte verwendet werden, die sowohl Nutzern als auch Crawlern den Kontext der verlinkten Seiten vermitteln. Ihre Website sollte schnell laden, da die Seitengeschwindigkeit ein Faktor ist, der die Crawling-Effizienz und die Menge der von Googlebot innerhalb des zugeteilten Crawl-Budgets gecrawlten Seiten beeinflusst.
Erstellen und übermitteln Sie eine XML-Sitemap an die Google Search Console, die Googlebot eine umfassende Liste aller zu indexierenden Seiten bereitstellt. Dies ist besonders wichtig für große Websites oder Seiten mit Inhalten, die nicht einfach über die interne Verlinkung auffindbar sind. Stellen Sie außerdem sicher, dass Ihre robots.txt-Datei korrekt konfiguriert ist, damit Googlebot die gewünschten Seiten indexieren und den Zugriff auf sensible Bereiche oder doppelte Inhalte blockieren kann. Seien Sie jedoch vorsichtig, keine wichtigen Seiten versehentlich zu blockieren, da diese sonst gar nicht indexiert werden.
Die Google Search Console ist ein unverzichtbares Tool, um zu überwachen, wie Googlebot mit Ihrer Website interagiert, und um Crawling-Probleme zu erkennen, die eine ordnungsgemäße Indexierung verhindern könnten. Der Bereich „Crawl-Statistiken“ liefert detaillierte Informationen darüber, wie viele Seiten Googlebot gecrawlt hat, wie viel Zeit er auf Ihrer Website verbracht hat und wie viele Fehler dabei aufgetreten sind. Sie können die durchschnittliche Antwortzeit Ihres Servers sehen, was sich direkt darauf auswirkt, wie effizient Googlebot Ihre Seiten crawlen kann – langsamere Server bedeuten, dass innerhalb desselben Zeitraums weniger Seiten gecrawlt werden.
Der Bericht „Indexabdeckung“ in der Google Search Console zeigt, welche Seiten erfolgreich indexiert wurden, welche Seiten Fehler aufweisen, die eine Indexierung verhindern, und welche Seiten vom Index ausgeschlossen sind. Diese Informationen sind wertvoll, um technische Probleme wie defekte Links, Serverfehler oder durch robots.txt blockierte Seiten zu identifizieren, die Sie möglicherweise nicht absichtlich blockiert haben. Mit dem URL-Prüftool können Sie außerdem testen, wie Googlebot eine bestimmte Seite sieht, ob er JavaScript-Inhalte rendern kann und ob alle Ressourcen zum ordnungsgemäßen Anzeigen der Seite zugänglich sind.
Jede Website hat ein „Crawl-Budget“ – die Anzahl der Seiten, die Googlebot innerhalb eines bestimmten Zeitraums auf Ihrer Website crawlt. Für die meisten Websites ist das Crawl-Budget kein limitierender Faktor, aber für sehr große Websites mit Tausenden oder Millionen von Seiten wird die Optimierung des Crawl-Budgets wichtig. Google weist das Crawl-Budget auf Grundlage von zwei Faktoren zu: Crawl-Kapazität (wie viel Ihr Server verkraftet) und Crawl-Nachfrage (wie wichtig Google Ihre Website einschätzt). Die Verbesserung der Seitengeschwindigkeit und das Beheben von Crawling-Fehlern erhöhen die Crawl-Kapazität, während qualitativ hochwertige, regelmäßig aktualisierte Inhalte die Crawl-Nachfrage steigern.
Um Ihr Crawl-Budget zu optimieren, entfernen Sie doppelte Inhalte, die Crawling-Ressourcen verschwenden, beheben Sie defekte Links und Weiterleitungsketten und entfernen Sie Seiten, die für Nutzer keinen Mehrwert bieten. Vermeiden Sie es, wichtige Seiten mit robots.txt oder noindex-Tags zu blockieren, und sorgen Sie dafür, dass Ihre Seitenstruktur es Googlebot ermöglicht, alle wichtigen Seiten mit wenigen Klicks von der Startseite aus zu erreichen. Aktualisieren Sie regelmäßig Ihre XML-Sitemap und entfernen Sie veraltete Seiten, damit Googlebot seine Crawling-Ressourcen auf die für Ihr Unternehmen wichtigsten Inhalte fokussieren kann.
Website-Betreiber stoßen häufig auf verschiedene Probleme, die verhindern, dass Googlebot ihre Seiten effektiv crawlt. Serverfehler (5xx-Statuscodes) zeigen an, dass Ihr Server Probleme bei der Beantwortung von Anfragen hat, was die Indexierung von Seiten verhindert. Weiterleitungsketten – bei denen eine Seite zu einer anderen weiterleitet, die wiederum zu einer dritten weiterleitet – verschwenden Crawl-Budget und verlangsamen die Indexierung. Blockierte Ressourcen, wie CSS- oder JavaScript-Dateien, die durch robots.txt gesperrt sind, können verhindern, dass Googlebot Ihre Seiten richtig rendert und versteht.
Soft-404-Fehler treten auf, wenn eine Seite einen 200-Statuscode (Erfolg) zurückgibt, aber wenig oder keinen tatsächlichen Inhalt enthält, was Googlebot verwirrt, ob die Seite indexiert werden sollte. Noindex-Tags, die versehentlich auf wichtige Seiten angewendet werden, verhindern deren Anzeige in den Suchergebnissen. Lange Ladezeiten reduzieren die Anzahl der Seiten, die Googlebot innerhalb des zugeteilten Budgets crawlen kann. Um diese Probleme zu beheben, sollten Sie Ihre Website regelmäßig mit der Google Search Console überprüfen, Server-Logs auf Crawling-Fehler überwachen und Tools wie Screaming Frog verwenden, um technische Probleme zu erkennen, bevor sie Ihre Sichtbarkeit in der Suche beeinträchtigen.
Im Jahr 2025 ist der Google Spider nach wie vor so wichtig wie eh und je, auch wenn sich seine Rolle an neue Technologien und Inhaltsformate angepasst hat. Googlebot kann inzwischen JavaScript rendern, das heißt, er kann auch von JavaScript-Frameworks dynamisch erzeugte Inhalte crawlen und indexieren. Er verarbeitet außerdem strukturierte Daten (Schema.org), um Seiteninhalte besser zu verstehen und Rich Snippets in den Suchergebnissen bereitzustellen. Durch Mobile-First-Indexierung priorisiert Googlebot das Crawlen und Indexieren der mobilen Version Ihrer Website, wodurch mobile Optimierung für den SEO-Erfolg unerlässlich wird.
Der Spider spielt auch eine entscheidende Rolle dabei, wie Google Spam erkennt und bekämpft, gehackte Inhalte identifiziert und sicherstellt, dass Suchergebnisse relevant und vertrauenswürdig bleiben. Während Suchmaschinen mit KI und Machine-Learning-Technologien weiterentwickelt werden, werden die Crawling- und Indexierungsfähigkeiten des Googlebot immer ausgefeilter, sodass Google die Nutzerintention besser verstehen und noch präzisere Suchergebnisse liefern kann. Zu verstehen, wie Googlebot arbeitet und die eigene Website entsprechend zu optimieren, bleibt einer der grundlegendsten Aspekte jeder SEO-Strategie.
Genau wie der Google Spider Ihre Inhalte crawlt und indexiert, hilft Ihnen PostAffiliatePro dabei, Ihre Affiliate-Marketing-Performance zu verfolgen und zu optimieren. Überwachen Sie jeden Klick, jede Conversion und jede Provision mit unserer branchenführenden Affiliate-Management-Plattform.
Crawler sammeln Daten und Informationen aus dem Internet, indem sie Websites besuchen und die Seiten lesen. Erfahren Sie mehr über sie.
Spiders sind Bots, die zum Spammen erstellt wurden und Ihrem Unternehmen viele Probleme bereiten können. Erfahren Sie mehr über sie im Artikel.
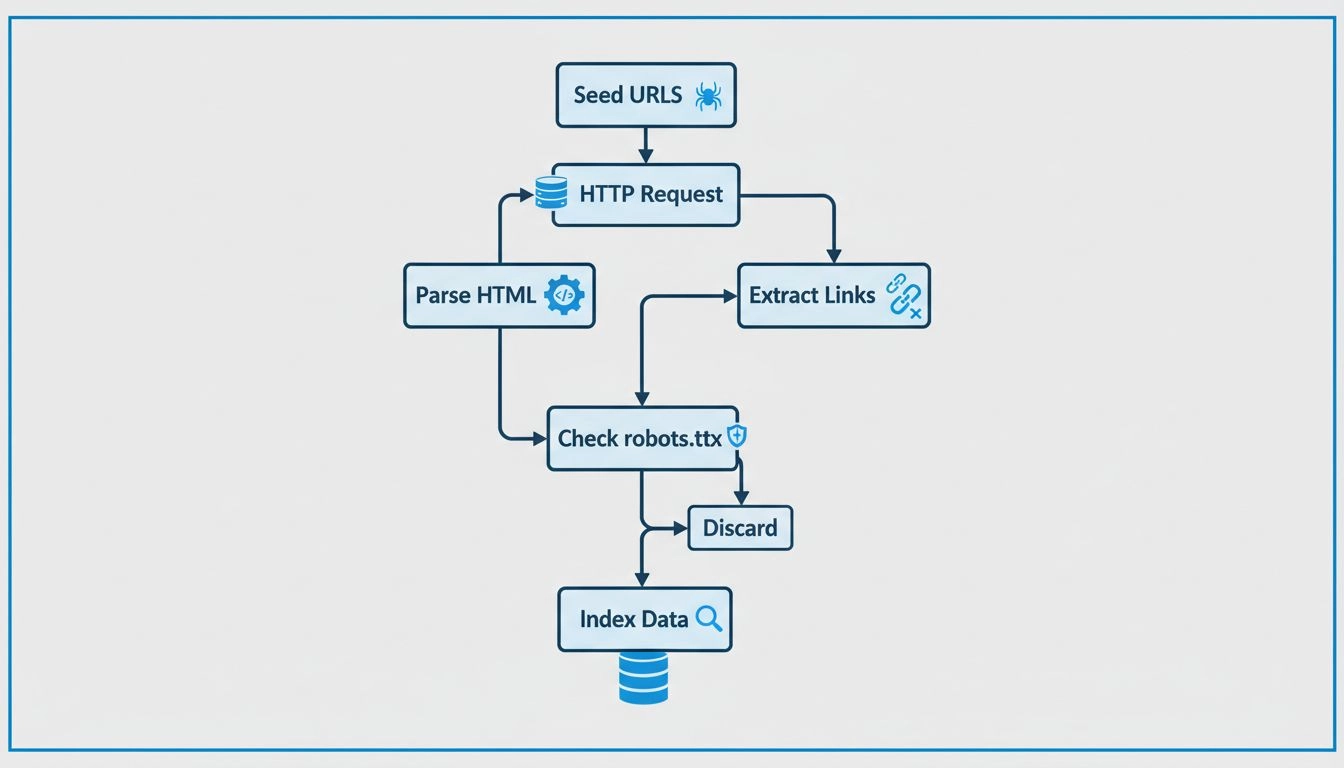
Erfahren Sie, wie Webcrawler arbeiten – von Seed-URLs bis zur Indexierung. Verstehen Sie den technischen Ablauf, Crawler-Typen, robots.txt-Regeln und wie Crawle...
Treten Sie unserer Gemeinschaft zufriedener Kunden bei und bieten Sie exzellenten Kundensupport mit Post Affiliate Pro.
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.