
Crawler und ihre Rolle beim Suchmaschinen-Ranking
Crawler sammeln Daten und Informationen aus dem Internet, indem sie Websites besuchen und die Seiten lesen. Erfahren Sie mehr über sie.
5 Min. Lesezeit
SEO
Crawlers
+4

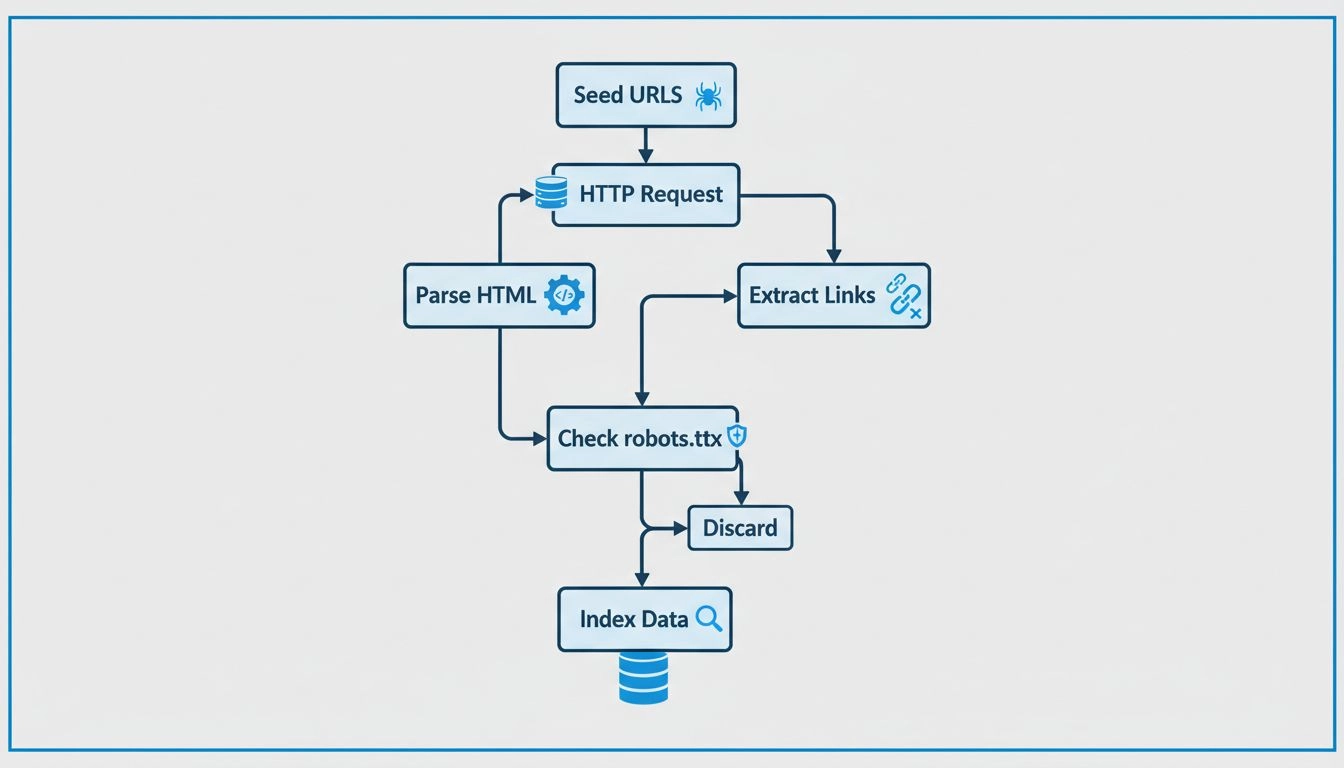
Erfahren Sie, wie Webcrawler arbeiten – von Seed-URLs bis zur Indexierung. Verstehen Sie den technischen Ablauf, Crawler-Typen, robots.txt-Regeln und wie Crawler SEO und Affiliate-Marketing beeinflussen.
Webcrawler funktionieren, indem sie HTTP-Anfragen an Websites senden, beginnend mit Seed-URLs, und Hyperlinks folgen, um neue Seiten zu entdecken. Sie parsen HTML-Inhalte, um Informationen zu extrahieren, befolgen robots.txt-Regeln und speichern die gesammelten Daten in durchsuchbaren Indizes. Sie besuchen systematisch Seiten, extrahieren Metadaten und Links und wiederholen den Prozess, um die Datenbanken von Suchmaschinen aktuell zu halten.
Webcrawler, auch als Spider oder Bots bekannt, sind automatisierte Programme, die systematisch das Internet durchsuchen, um Webinhalte zu entdecken, herunterzuladen und zu analysieren. Diese intelligenten Agenten bilden das Rückgrat der Suchmaschinen-Infrastruktur und ermöglichen Plattformen wie Google, Bing und anderen Suchdiensten, umfassende Indizes von Milliarden von Webseiten zu erstellen. Der Hauptzweck von Webcrawlern ist es, Informationen von Websites zu sammeln und zu organisieren, damit Suchmaschinen bei Suchanfragen der Nutzer schnell relevante Ergebnisse liefern können. Ohne Webcrawler könnten Suchmaschinen keine neuen Inhalte entdecken oder ihre Indizes mit den neuesten verfügbaren Informationen aktuell halten.
Die Bedeutung von Webcrawlern geht weit über die reine Suchfunktion hinaus. Sie bilden die Grundlage zahlreicher digitaler Anwendungen wie Preisvergleichsportale, Content-Aggregatoren, Marktforschungsplattformen, SEO-Analysetools und Webarchivierungsdienste. Für Affiliate-Marketer und Netzwerkbetreiber, wie sie PostAffiliatePro nutzen, ist das Verständnis der Funktionsweise von Crawlern essenziell, um sicherzustellen, dass Affiliate-Inhalte, Produktseiten und Werbematerialien von Suchmaschinen korrekt entdeckt und indexiert werden. Diese Sichtbarkeit wirkt sich direkt auf den organischen Traffic, die Lead-Generierung und letztendlich auf Provisionsmöglichkeiten aus.
Webcrawler folgen einem methodischen und strukturierten Prozess, um das Internet systematisch zu erkunden. Der Prozess beginnt mit Seed-URLs, das sind bekannte Startpunkte wie Homepage-URLs, XML-Sitemaps oder zuvor gecrawlte Seiten. Diese Seed-URLs dienen als Einstiegspunkt für die Reise des Crawlers durch das Web. Der Crawler pflegt eine Warteschlange von URLs, die besucht werden sollen, oft als „Crawl Frontier“ bezeichnet, die kontinuierlich wächst, wenn während des Crawlens neue Links entdeckt werden.
Wenn ein Crawler eine URL erreicht, sendet er eine HTTP-Anfrage an den Webserver, der diese Seite hostet. Der Server antwortet, indem er den HTML-Inhalt der Seite zurückschickt – ähnlich wie ein Browser eine Seite lädt, wenn Sie sie besuchen. Der Crawler analysiert dann diesen HTML-Code, um wertvolle Informationen wie Seiteninhalte, Metadaten (wie Titel und Beschreibung), Bilder, Videos und vor allem Hyperlinks zu anderen Seiten zu extrahieren. Diese Link-Extraktion ist entscheidend, weil sie es dem Crawler ermöglicht, neue, noch nicht besuchte URLs zu entdecken, die dann für zukünftige Besuche der Crawl-Warteschlange hinzugefügt werden.
| Crawler-Prozessstufe | Beschreibung | Wichtige Aktionen |
|---|---|---|
| Initialisierung | Starten des Crawl-Prozesses | Seed-URLs laden, Crawl-Warteschlange initialisieren |
| Anfrage & Abruf | Abrufen des Seiteninhalts | HTTP-Anfragen senden, HTML-Antworten empfangen |
| HTML-Analyse | Struktur der Seite parsen | Text, Metadaten, Links, Medien extrahieren |
| Link-Extraktion | Neue URLs finden | Hyperlinks identifizieren, zur Warteschlange hinzufügen |
| robots.txt-Prüfung | Einhaltung der Seitenregeln | Crawl-Berechtigungen vor dem Besuch prüfen |
| Inhaltspeicherung | Informationen speichern | Daten im durchsuchbaren Index ablegen |
| Priorisierung | Auswahl der nächsten Seiten | URLs nach Wichtigkeit und Relevanz einstufen |
| Wiederholung | Zyklus fortsetzen | Nächste URL in der Warteschlange verarbeiten |
Bevor ein Crawler eine neue URL auf einer Domain besucht, prüfen verantwortungsvolle Crawler die robots.txt-Datei im Root-Verzeichnis dieser Domain. Diese Datei enthält Anweisungen, mit denen Website-Betreiber den Crawlern mitteilen, welche Seiten gecrawlt werden dürfen und welche nicht. Ein Website-Betreiber kann z. B. robots.txt einsetzen, um Crawler vom Zugriff auf sensible Seiten, doppelte Inhalte oder ressourcenintensive Bereiche auszuschließen. Die meisten seriösen Suchmaschinen-Crawler respektieren diese Anweisungen, um gute Beziehungen zu Website-Betreibern zu pflegen und Performanceprobleme zu vermeiden.
Richten Sie erweitertes Tracking in wenigen Minuten ein. Keine Kreditkarte erforderlich.
Moderne Webcrawler haben sich erheblich weiterentwickelt, um die Komplexität zeitgemäßer Websites zu bewältigen. Viele heutige Seiten verwenden JavaScript, um Inhalte dynamisch nach dem Laden zu generieren, sodass die initiale HTML-Antwort nicht den gesamten Seiteninhalt enthält. Fortgeschrittene Crawler nutzen nun Headless-Browser, um JavaScript auszuführen und dynamisch geladene Inhalte zu erfassen, die traditionelle Crawler nicht sehen würden. Diese Fähigkeit ist für das Crawlen von Single-Page-Anwendungen, interaktiven Dashboards und modernen Webanwendungen, die stark auf Client-seitiges Rendering setzen, unerlässlich.
Crawler setzen ausgeklügelte Priorisierungsalgorithmen ein, um ihr Crawl-Budget – die Anzahl der Seiten, die sie in einem bestimmten Zeitraum crawlen können – effizient zu nutzen. Diese Algorithmen berücksichtigen verschiedene Faktoren wie Seitenautorität (bestimmt durch Qualität und Anzahl der Backlinks), interne Link-Struktur, Aktualität der Inhalte, Traffic-Volumen und Domain-Reputation. Seiten mit hoher Autorität und häufig aktualisierte Inhalte werden häufiger gecrawlt, während weniger wichtige oder statische Seiten seltener besucht oder ganz ausgelassen werden. Diese intelligente Priorisierung stellt sicher, dass Crawler ihre Ressourcen auf die wertvollsten und am häufigsten geänderten Inhalte konzentrieren.
Crawl-Delay und Ratenbegrenzung sind wichtige Mechanismen, die verhindern, dass Crawler Webserver überlasten. Verantwortungsvolle Crawler legen Pausen zwischen den Anfragen ein und befolgen die Crawl-Delay-Anweisungen, die in robots.txt-Dateien festgelegt sind. Dieses höfliche Crawl-Verhalten schützt die Web-Performance und Nutzererfahrung, indem sichergestellt wird, dass der Crawler-Traffic keine übermäßigen Serverressourcen beansprucht. Websites, die langsam laden oder Fehler zurückgeben, werden von Crawlern oft seltener besucht, da diese automatisch das Tempo drosseln, um Probleme zu vermeiden.
Verschiedene Arten von Webcrawlern erfüllen unterschiedliche Aufgaben im digitalen Ökosystem. Allgemeine Webcrawler werden von großen Suchmaschinen eingesetzt, um das gesamte Internet ohne Einschränkungen zu crawlen und umfassende Indizes für Suchergebnisse zu erstellen. Diese Crawler sind auf maximale Abdeckung ausgelegt und laufen kontinuierlich, um neue Inhalte zu entdecken und bestehende Indizes zu aktualisieren. Vertikale oder spezialisierte Crawler konzentrieren sich auf bestimmte Branchen oder Content-Typen, z. B. Job-Crawler, die Stellenbörsen durchsuchen, Preisvergleichs-Crawler, die Preisdaten von E-Commerce-Seiten sammeln, oder Forschungs-Crawler, die wissenschaftliche Publikationen indexieren.
Inkrementelle Crawler sind auf Effizienz ausgelegt, indem sie sich nur auf neue oder kürzlich geänderte Inhalte konzentrieren, statt regelmäßig ganze Websites neu zu crawlen. Dieser Ansatz reduziert die Serverbelastung und den Bandbreitenverbrauch erheblich und hält die Indizes dennoch relativ aktuell. Fokussierte Crawler nutzen ausgefeilte Algorithmen, um gezielt nach Inhalten zu bestimmten Themen oder Schlüsselwörtern zu suchen und priorisieren Seiten, die wahrscheinlich relevante Informationen enthalten. Echtzeit-Crawler überwachen Websites kontinuierlich und aktualisieren ihre gesammelten Daten in Echtzeit oder nahezu Echtzeit, was sie ideal für Nachrichten-Aggregation oder Social-Media-Monitoring macht.
Parallele Crawler und verteilte Crawler stehen für das Infrastruktur-intensive Ende des Crawler-Spektrums. Parallele Crawler arbeiten gleichzeitig auf mehreren Maschinen oder Threads, um die Crawling-Geschwindigkeit und den Durchsatz deutlich zu erhöhen. Verteilte Crawler teilen die Arbeitslast auf mehrere Server oder Rechenzentren auf und können so riesige Datenmengen effizient verarbeiten. Große Suchmaschinen wie Google nutzen verteilte Crawler-Architekturen, um die Milliarden von Seiten im Internet zu bewältigen.
Erfahren Sie als Erster von neuen Funktionen und Produkt-Updates.
Webcrawler spielen eine grundlegende Rolle für die Suchmaschinenoptimierung, da sie bestimmen, welche Seiten indexiert werden und wie Suchmaschinen Ihre Inhalte verstehen. Wenn Crawler Ihre Seiten nicht erreichen können, erscheinen diese Seiten ungeachtet ihrer Qualität oder Relevanz nicht in den Suchergebnissen. Häufige Crawling-Probleme, die eine richtige Indexierung verhindern, sind Seiten, die durch robots.txt-Anweisungen blockiert sind, defekte interne Links, die zu 404-Fehlern führen, langsame Ladezeiten, die zu Crawler-Timeouts führen, und JavaScript-Probleme, durch die Crawler dynamisch generierte Inhalte nicht sehen können.
Website-Betreiber können den Crawler-Zugriff durch verschiedene Strategien optimieren. Klare Seitenarchitektur mit logischen Navigationshierarchien hilft Crawlern, die Beziehungen und Wichtigkeit der Seiten zu erfassen. Interne Verlinkungen signalisieren Crawlern, welche Seiten besonders wichtig sind, und helfen, das Crawl-Budget effizient auf der Website zu verteilen. XML-Sitemaps listen explizit alle wichtigen Seiten auf und stellen sicher, dass Crawler keinen Content übersehen – selbst auf großen oder komplexen Websites. Schnelle Ladezeiten ermöglichen es Crawlern, innerhalb des ihnen zugewiesenen Crawl-Budgets mehr Seiten zu besuchen, während frische, regelmäßig aktualisierte Inhalte signalisieren, dass eine Website häufigeren Crawler-Besuch verdient.
Für Affiliate-Marketer, die Plattformen wie PostAffiliatePro nutzen, ist ein ordnungsgemäßer Crawler-Zugriff entscheidend, um organischen Traffic auf Affiliate-Inhalte zu lenken. Werden Ihre Affiliate-Produktseiten, Vergleichsartikel und Werbeinhalte korrekt gecrawlt und indexiert, haben sie die Chance, in Suchergebnissen zu ranken und qualifizierten Traffic zu generieren. Schlechte Crawlability kann zu verpassten Indexierungsmöglichkeiten und geringerer Sichtbarkeit Ihrer Affiliate-Angebote führen.
Website-Betreiber haben verschiedene Möglichkeiten, zu steuern, wie Crawler mit ihren Seiten interagieren. Die robots.txt-Datei ist das wichtigste Werkzeug und enthält Anweisungen, welche User-Agents (Crawler-Typen) auf welche Teile der Website zugreifen dürfen. Eine gut konfigurierte robots.txt kann verhindern, dass Crawler Ressourcen für doppelte Inhalte, Staging-Umgebungen oder ressourcenintensive Seiten verschwenden, während sie wichtige Inhalte uneingeschränkt crawlen dürfen. Das robots-Meta-Tag erscheint im HTML einzelner Seiten und bietet Kontrolle auf Seitenebene, sodass einzelne Seiten von der Indexierung ausgeschlossen oder ihre Links ignoriert werden können.
Das nofollow-Link-Attribut weist Crawler an, bestimmten Hyperlinks nicht zu folgen – nützlich, um Crawler vom Folgen von Links zu nicht vertrauenswürdigen externen Seiten oder nutzergenerierten Inhalten abzuhalten. Diese Kontrollmechanismen arbeiten zusammen, um Website-Betreibern eine feingranulare Steuerung des Crawler-Verhaltens zu ermöglichen und gleichzeitig gute Beziehungen zu Suchmaschinen zu pflegen. Es ist jedoch zu beachten, dass bösartige Webscraper und aggressive Bots diese Anweisungen oft ignorieren, weshalb zusätzliche Sicherheitsmaßnahmen wie Ratenbegrenzung und Bot-Erkennung manchmal notwendig sind.
Für Betreiber von Affiliate-Netzwerken und Marketer hat das Verständnis des Crawler-Verhaltens direkten Einfluss auf den Geschäftserfolg. Crawler bestimmen die Sichtbarkeit von Affiliate-Produktseiten, Vergleichsinhalten und Werbematerialien in den Suchergebnissen. Wenn PostAffiliatePro-Nutzer ihre Affiliate-Websites für ein korrektes Crawling optimieren, erhöhen sie die Wahrscheinlichkeit, dass ihre Inhalte von Suchmaschinen entdeckt und für relevante Keywords gerankt werden. Diese organische Sichtbarkeit führt zu qualifiziertem Traffic auf Affiliate-Angebote, steigert die Conversion-Chancen und die Provisionsumsätze.
Affiliate-Netzwerke profitieren in mehrfacher Hinsicht von Crawler-Aktivitäten. Suchmaschinen-Crawler tragen dazu bei, Affiliate-Inhalte im Internet zu verbreiten, was die Markenbekanntheit und Reichweite erhöht. Crawler ermöglichen es auch Preisvergleichsseiten und Content-Aggregatoren, Affiliate-Produkte zu entdecken und zu präsentieren – so entstehen zusätzliche Traffic-Quellen. Affiliate-Marketer sollten sich jedoch auch der Gefahr durch bösartige Crawler und Scraper bewusst sein, die Affiliate-Inhalte kopieren oder Klickbetrug betreiben könnten. Die Implementierung geeigneter Ratenbegrenzungen, Bot-Erkennung und Inhaltschutzmaßnahmen hilft, die Integrität des Affiliate-Netzwerks zu sichern und gleichzeitig legitimen Crawlern den Zugang zu ermöglichen.
PostAffiliatePro bietet umfassende Tracking- und Reporting-Funktionen, die eine optimale Crawler-Optimierung ergänzen. Indem Sie sicherstellen, dass Ihre Affiliate-Inhalte korrekt gecrawlt und indexiert werden und dies mit dem fortschrittlichen Tracking und der Analyse von PostAffiliatePro kombinieren, können Sie die Sichtbarkeit und Profitabilität Ihres Affiliate-Netzwerks maximieren. Das Echtzeit-Provisionstracking und intelligente Reporting der Plattform helfen Ihnen dabei, zu verstehen, welche Affiliate-Kanäle den wertvollsten Traffic liefern, sodass Sie Ihre Netzwerkstrategie entsprechend optimieren können.
Genauso wie Webcrawler systematisch Inhalte entdecken und indexieren, verfolgt und optimiert PostAffiliatePro systematisch Ihre Affiliate-Beziehungen. Unsere Plattform bietet Echtzeit-Tracking, umfassende Berichte und intelligentes Provisionsmanagement, um Ihnen beim Aufbau eines florierenden Affiliate-Netzwerks zu helfen.
Crawler sammeln Daten und Informationen aus dem Internet, indem sie Websites besuchen und die Seiten lesen. Erfahren Sie mehr über sie.
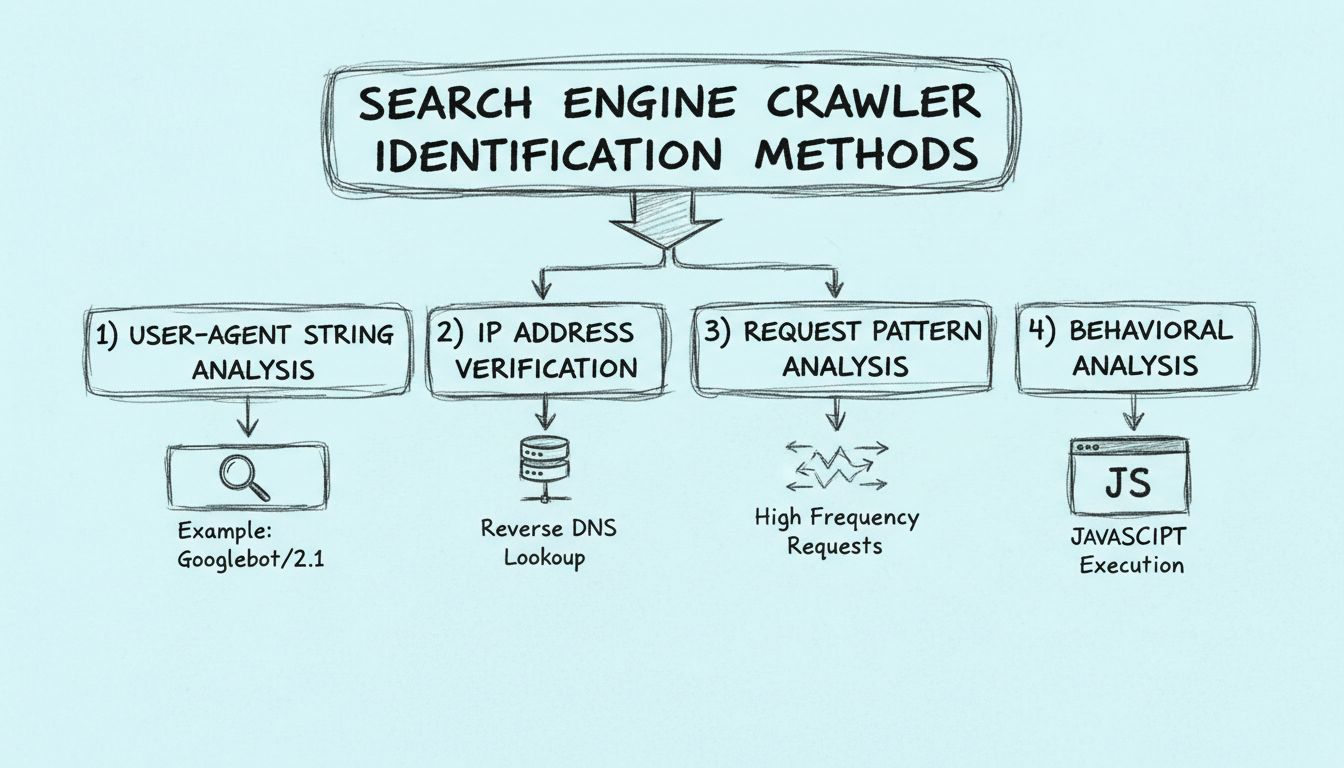
Erfahren Sie, wie Suchmaschinen-Crawler anhand von User-Agent-Strings, IP-Adressen, Anfrage-Mustern und Verhaltensanalysen erkannt werden können. Ein unverzicht...
Spiders sind Bots, die zum Spammen erstellt wurden und Ihrem Unternehmen viele Probleme bereiten können. Erfahren Sie mehr über sie im Artikel.
Treten Sie unserer Gemeinschaft zufriedener Kunden bei und bieten Sie exzellenten Kundensupport mit Post Affiliate Pro.
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.