
SEO-Spider: Warum sie für Ihre Website wichtig sind
Spiders sind Bots, die zum Spammen erstellt wurden und Ihrem Unternehmen viele Probleme bereiten können. Erfahren Sie mehr über sie im Artikel.
4 Min. Lesezeit
SEO
DigitalMarketing
+3
Erfahren Sie, warum Webcrawler Spinnen genannt werden, wie sie funktionieren und welche entscheidende Rolle sie bei der Indexierung von Suchmaschinen spielen. Entdecken Sie die technischen Mechanismen hinter dem Web-Crawling im Jahr 2025.
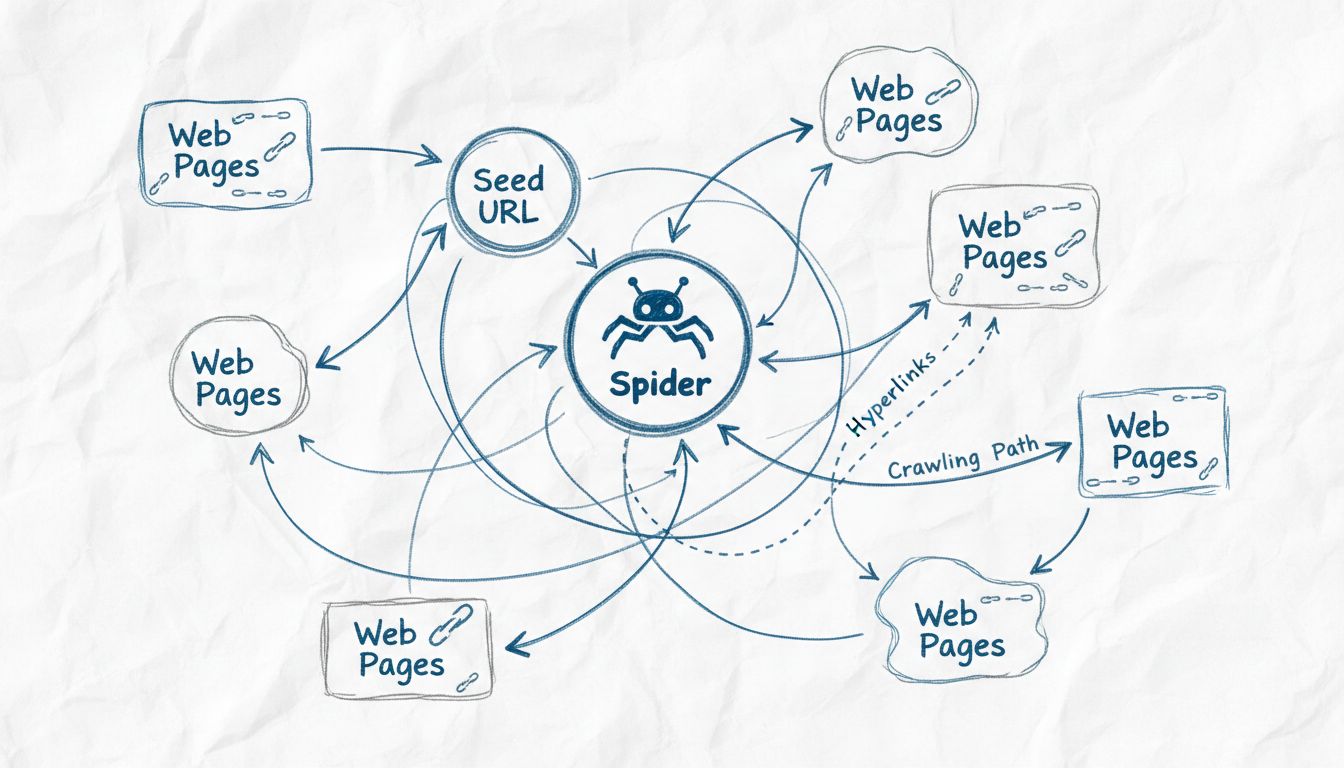
Webcrawler werden Spinnen genannt, weil sie systematisch das Web durchforsten, indem sie Links von einer Seite zur nächsten folgen – ähnlich wie eine Spinne ihr Netz durchquert. Der Begriff 'Spinne' ist eine treffende Metapher für diese automatisierten Bots, die das vernetzte Netzwerk von Websites durchqueren, um Webinhalte für Suchmaschinen zu entdecken, zu indexieren und zu organisieren.
Der Begriff „Spinne“ für Webcrawler stammt aus einem einfallsreichen metaphorischen Vergleich zwischen der Art und Weise, wie diese automatisierten Bots das Internet durchqueren, und wie echte Spinnen ihre Netze durchlaufen. Genau wie eine Spinne ein komplexes Netz webt, um Informationen über ihre Umgebung zu erfassen und zu organisieren, durchqueren Webcrawler das vernetzte Geflecht von Hyperlinks im World Wide Web, um digitale Inhalte zu entdecken, zu analysieren und zu organisieren. Die Metapher ist besonders passend, weil beide Entitäten systematisch durch komplexe Netzwerke arbeiten, indem sie Pfaden folgen, um neue Ziele zu erreichen und Informationen zu sammeln. Diese Namenskonvention ist so in der Technologie verankert, dass die Begriffe „Spinne“, „Crawler“ und „Bot“ inzwischen austauschbar verwendet werden, wenn es um Web-Indexierungstechnologie geht. Die visuelle und konzeptionelle Ähnlichkeit zwischen einem Spinnennetz und der Struktur des Internets macht diese Terminologie sowohl für Fachleute als auch für allgemeine Nutzer eingängig und einprägsam.
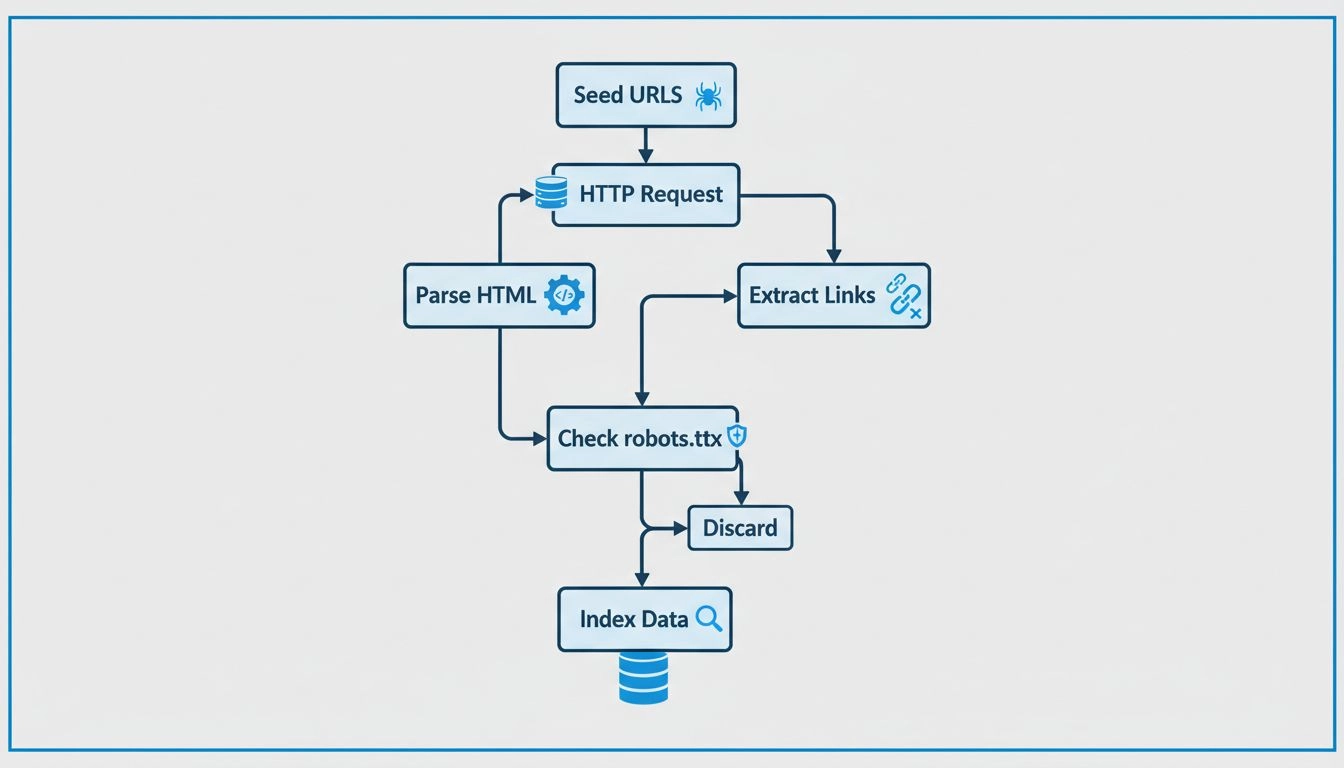
Webspinnen arbeiten nach einem ausgefeilten, aber systematischen Prozess, der mit einem einzigen Einstiegspunkt beginnt, der als „Seed-URL“ bezeichnet wird. Von diesem Startpunkt aus analysiert die Spinne den HTML-Code der Webseite und extrahiert alle dort vorhandenen Hyperlinks. Anschließend folgt die Spinne diesen Links zu neuen Seiten und wiederholt diesen Vorgang kontinuierlich, um ihre Reichweite im Web zu erweitern. Dieser methodische Ansatz ermöglicht es Spinnen, Millionen miteinander verbundener Seiten zu entdecken, ohne manuelle Steuerung oder menschliches Eingreifen zu benötigen. Die Spinne verwaltet eine sogenannte „Crawl-Frontier“, also eine Warteschlange von URLs, die entdeckt, aber noch nicht besucht wurden. Basierend auf spezifischen Crawling-Richtlinien und Algorithmen priorisiert die Spinne, welche URLs als Nächstes besucht werden sollen, wobei Faktoren wie Seitenwichtigkeit, Aktualisierungshäufigkeit und Relevanz für die Indexierungsziele der Suchmaschine berücksichtigt werden.
Richten Sie erweitertes Tracking in wenigen Minuten ein. Keine Kreditkarte erforderlich.
Moderne Webspinnen basieren auf einer ausgefeilten technischen Architektur, die es ihnen ermöglicht, riesige Datenmengen effizient zu verarbeiten. Zu den Kernkomponenten eines Webcrawlers gehören das URL-Frontier-Management-System, das URLs für das Crawling organisiert und priorisiert; der Abrufmechanismus, der Seiteninhalte mit hoher Geschwindigkeit herunterlädt; die Parsing-Engine, die Links und Metadaten aus dem HTML extrahiert; und das Indexierungssystem, das die verarbeiteten Informationen für die Suchabfrage speichert. Webspinnen müssen außerdem Höflichkeitsrichtlinien implementieren, um Zielserver nicht mit zu vielen Anfragen zu überlasten, Wiederbesuchs-Richtlinien, um zu bestimmen, wie häufig Seiten für Updates erneut gecrawlt werden sollen, und Auswahlrichtlinien, um zu entscheiden, welche Links am wertvollsten sind. Moderne Spinnen sind in der Lage, auch JavaScript- und AJAX-Inhalte zu verarbeiten, obwohl sie weiterhin Standard-HTML für eine zuverlässige Inhaltserkennung bevorzugen. Die verteilte Struktur des modernen Crawlings bedeutet, dass groß angelegte Spinnen gleichzeitig auf mehreren Servern laufen, sodass sie verschiedene Websites parallel crawlen und so Effizienz und Reichweite erheblich steigern.
Obwohl die Begriffe „Spinne“ und „Crawler“ oft synonym verwendet werden, ist es wichtig zu verstehen, dass sie dieselbe Technologie mit unterschiedlichen Namenskonventionen bezeichnen. Webspinnen unterscheiden sich jedoch deutlich von Web-Scrapern, mit denen sie manchmal verwechselt werden. Der Hauptunterschied liegt in Ziel und Umfang: Webcrawler dienen der allgemeinen Informationssammlung über Websites und deren Struktur, indem sie breitflächig Links im Web folgen, um umfassende Indizes zu erstellen. Webspinnen, speziell von Suchmaschinen eingesetzt, konzentrieren sich auf die Indexierung von Textinhalten, um diese auffindbar und durchsuchbar zu machen. Web-Scraper hingegen sind Präzisionswerkzeuge, die gezielt bestimmte Datenelemente von Websites extrahieren, z. B. Produktpreise, Kontaktdaten oder Bewertungen. Scraper richten sich in der Regel auf bestimmte Websites oder Datentypen, anstatt das Web breit zu crawlen. Darüber hinaus respektieren Crawler und Spinnen im Allgemeinen robots.txt-Dateien und die Nutzungsbedingungen von Websites, während Scraper oft ohne solche Einschränkungen arbeiten. Das Verständnis dieser Unterschiede ist für Website-Betreiber und Entwickler entscheidend, um zu steuern, wie ihre Inhalte von automatisierten Systemen abgerufen und indexiert werden.
Erfahren Sie als Erster von neuen Funktionen und Produkt-Updates.
Webspinnen sind absolut grundlegend für die Funktionsweise von Suchmaschinen und ihren Nutzen für Nutzer weltweit. Ohne das kontinuierliche Crawling und die Indexierung von Webinhalten durch Spinnen hätten Suchmaschinen keine Möglichkeit zu wissen, welche Websites existieren, welche Inhalte sie enthalten oder wie relevant diese Inhalte für Nutzeranfragen sind. Wenn eine Spinne eine Webseite crawlt, bewertet sie zahlreiche Faktoren, darunter Seitenstruktur, Inhaltsrelevanz, Keyword-Nutzung und Signale zur Nutzererfahrung. Diese Informationen werden dann in riesigen Indizes gespeichert, die Suchmaschinen nutzen, um Nutzeranfragen mit den relevantesten Ergebnissen abzugleichen. Die Qualität und Häufigkeit des Spinnencrawlings wirkt sich direkt darauf aus, wie schnell neue Inhalte in den Suchergebnissen erscheinen und wie präzise Suchmaschinen Seiten ranken können. Suchmaschinen wie Google, Bing, Baidu und Yahoo unterhalten jeweils eigene, proprietäre Spinnen-Bots – Googlebot, Bingbot, Baiduspider und Slurp – die jeweils über einzigartige Algorithmen und Crawling-Strategien verfügen, die auf die spezifischen Ziele und Nutzergruppen der jeweiligen Suchmaschine abgestimmt sind.
| Spider Bot | Suchmaschine | Hauptfunktion | Crawling-Strategie | Wichtige Merkmale |
|---|---|---|---|---|
| Googlebot | Indexiert Webseiten für die Google-Suche | Verteiltes Crawling mit mobilen und Desktop-Varianten | Verarbeitet JavaScript, priorisiert Mobile-First-Indexierung, berücksichtigt Crawl-Budget | |
| Bingbot | Microsoft Bing | Indexiert Webseiten für Bing-Suche | Paralleles Crawling über mehrere Server | Effiziente Bandbreitennutzung, beachtet robots.txt, unterstützt mehrere Inhaltstypen |
| Baiduspider | Baidu | Indexiert Webseiten für Baidu-Suche | Optimiert für chinesischsprachige Inhalte | Speziell für asiatische Webinhalte, verarbeitet vereinfachtes und traditionelles Chinesisch |
| DuckDuckBot | DuckDuckGo | Indexiert Webseiten für datenschutzorientierte Suche | Rücksichtsvolles Crawling mit Fokus auf Datenschutz | Minimale Datenerfassung, respektiert Nutzer-Privatsphäre |
| YandexBot | Yandex | Indexiert Webseiten für Yandex-Suche | Verteiltes Crawling mit regionaler Optimierung | Optimiert für russische und osteuropäische Inhalte |
Website-Betreiber haben verschiedene Werkzeuge und Strategien zur Verfügung, um zu optimieren, wie Spinnen ihre Inhalte crawlen und indexieren. Die Erstellung einer umfassenden sitemap.xml-Datei bietet den Spinnen eine klare Übersicht aller Seiten, die indexiert werden sollen, verbessert die Crawling-Effizienz erheblich und stellt sicher, dass keine wichtigen Seiten übersehen werden. Die Optimierung von Meta-Tags, einschließlich Title-Tags und Meta-Beschreibungen, hilft Spinnen, den Seiteninhalt zu verstehen und verbessert die Darstellung der Seiten in den Suchergebnissen. Durch eine gut strukturierte robots.txt-Datei können Website-Betreiber Spinnen gezielt auf wichtige Inhalte lenken und von Seiten fernhalten, die nicht indexiert werden sollen, z. B. Admin-Bereiche oder doppelte Inhalte. Regelmäßige Aktualisierungen und das Hinzufügen neuer Inhalte fördern, dass Spinnen Websites häufiger besuchen, wodurch die Indizes aktuell bleiben und die Sichtbarkeit in Suchmaschinen steigt. Website-Betreiber sollten zudem auf eine saubere und logische Seitenarchitektur achten, mit klarer hierarchischer Navigation, damit Spinnen alle Seiten leicht entdecken können. Die Verbesserung der Ladegeschwindigkeit ist entscheidend, da Spinnen über ein begrenztes Crawl-Budget verfügen – also die Ressourcen, die Suchmaschinen für das Crawling einer bestimmten Seite bereitstellen – und schnellere Seiten erlauben es den Spinnen, mehr Inhalte innerhalb dieses Budgets zu crawlen.
Trotz ihrer ausgefeilten Technik stehen Webspinnen vor zahlreichen Herausforderungen, die ihre Effektivität begrenzen können. Dynamische Inhalte, die durch JavaScript erzeugt werden, stellen ein großes Hindernis dar, da nicht alle Spinnen JavaScript ausführen können, um Seiten so darzustellen, wie Nutzer sie sehen. Von Websites gesetzte Rate-Limits beschränken, wie viele Anfragen Spinnen innerhalb einer bestimmten Zeit stellen dürfen, was das vollständige Indexieren großer Websites verhindern kann. CAPTCHA-Herausforderungen und andere Anti-Bot-Maßnahmen können den Spinnen den Zugriff auf Inhalte verwehren, wobei legitime Suchmaschinen-Spinnen in der Regel auf Whitelists stehen. Doppelte Inhalte unter mehreren URLs verwirren Spinnen darüber, welche Version indexiert und gerankt werden soll, was die Sichtbarkeit in Suchmaschinen beeinträchtigen kann. Crawler-Traps – absichtliche oder versehentliche Endlosschleifen in der Website-Struktur – können Spinnen-Ressourcen verschwenden und Crawl-Budgets verbrauchen, ohne produktive Indexierung zu liefern. Darüber hinaus kann das exponentielle Wachstum der Webinhalte nicht vollständig gecrawlt und indexiert werden, weshalb ausgefeilte Algorithmen erforderlich sind, um die wichtigsten Inhalte für die Indexierung zu priorisieren. Passwortgeschützte Seiten und authentifizierte Inhalte bleiben für öffentliche Spinnen weitgehend unzugänglich, wodurch die Indexierung privater oder mitgliedschaftsbasierter Inhalte eingeschränkt ist.
Die Technologie der Webspinnen entwickelt sich rasant weiter, während das Internet wächst und immer komplexer wird. Moderne Spinnen sind zunehmend in der Lage, fortschrittliche Webtechnologien wie Single-Page-Applications, Progressive Web Apps und dynamische Inhaltswiedergabe zu bewältigen. Künstliche Intelligenz und maschinelles Lernen werden in Spinnen-Algorithmen integriert, um Kontext, Nutzerintention und Seitenqualität besser zu verstehen. Der Aufstieg generativer KI schafft neue Anforderungen an das Web-Crawling, da KI-Systeme kontinuierlich aktualisierte, relevante und akkurate Informationen benötigen. Enterprise-Webcrawler sind zunehmend ausgefeilt und ermöglichen es Unternehmen, ihre eigenen Websites für interne Suche, Content-Management und Performance-Monitoring zu crawlen. Der Fokus auf Crawl-Effizienz ist gestiegen, da Websites immer größer und komplexer werden – Spinnen implementieren heute intelligentere Priorisierungsalgorithmen, um den Wert jeder Crawl-Anfrage zu maximieren. Datenschutzaspekte prägen ebenfalls die Entwicklung von Spinnen, wobei der Schutz der Privatsphäre der Nutzer immer stärker berücksichtigt wird, während effektive Inhaltsentdeckung und Indexierung weiterhin möglich bleiben sollen. In Zukunft werden Webspinnen voraussichtlich noch intelligenter und effizienter, indem sie fortschrittliche Technologien einsetzen, um sich in einer zunehmend komplexen digitalen Landschaft zurechtzufinden und gleichzeitig Website-Richtlinien und Nutzer-Privatsphäre zu respektieren.
So wie Webspinnen systematisch das gesamte Web durchforsten und indexieren, verfolgt und optimiert PostAffiliatePro systematisch jede Affiliate-Beziehung in Ihrem Netzwerk. Unsere fortschrittliche Tracking-Technologie stellt sicher, dass keine Provision verloren geht und keine Gelegenheit verpasst wird.
Spiders sind Bots, die zum Spammen erstellt wurden und Ihrem Unternehmen viele Probleme bereiten können. Erfahren Sie mehr über sie im Artikel.
Computerspinnen sind spezielle Bots, die entwickelt wurden, um Ihre E-Mail-Adresse oder Webseite zu spammen. Um Angriffe auf Ihre Seiten zu verhindern, nutzen S...
Erfahren Sie, wie Webcrawler arbeiten – von Seed-URLs bis zur Indexierung. Verstehen Sie den technischen Ablauf, Crawler-Typen, robots.txt-Regeln und wie Crawle...
Treten Sie unserer Gemeinschaft zufriedener Kunden bei und bieten Sie exzellenten Kundensupport mit Post Affiliate Pro.
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.