
Wie Sie überprüfen, ob Ihre Website von Google indexiert ist
Erfahren Sie 7 bewährte Methoden, um zu überprüfen, ob Ihre Website von Google indexiert wurde. Nutzen Sie die Google Search Console, Site-Operatoren, URL-Inspe...
10 Min. Lesezeit
Erfahren Sie, was Seitenindexierung bedeutet, warum Seiten von Google nicht indexiert werden und wie Sie Indexierungsprobleme beheben. Entdecken Sie technische Lösungen und Best Practices für 2025.
Wenn eine Seite nicht indexiert ist, bedeutet das, dass die Suchmaschine sie nicht in ihre Datenbank aufgenommen hat und sie daher nicht in den Suchergebnissen erscheint. Dies kann durch technische Probleme wie Noindex-Tags oder robots.txt-Sperren, Crawling-Fehler, doppelte Inhalte, schlechte Qualität oder einfach dadurch verursacht werden, dass die Seite noch nicht entdeckt wurde.
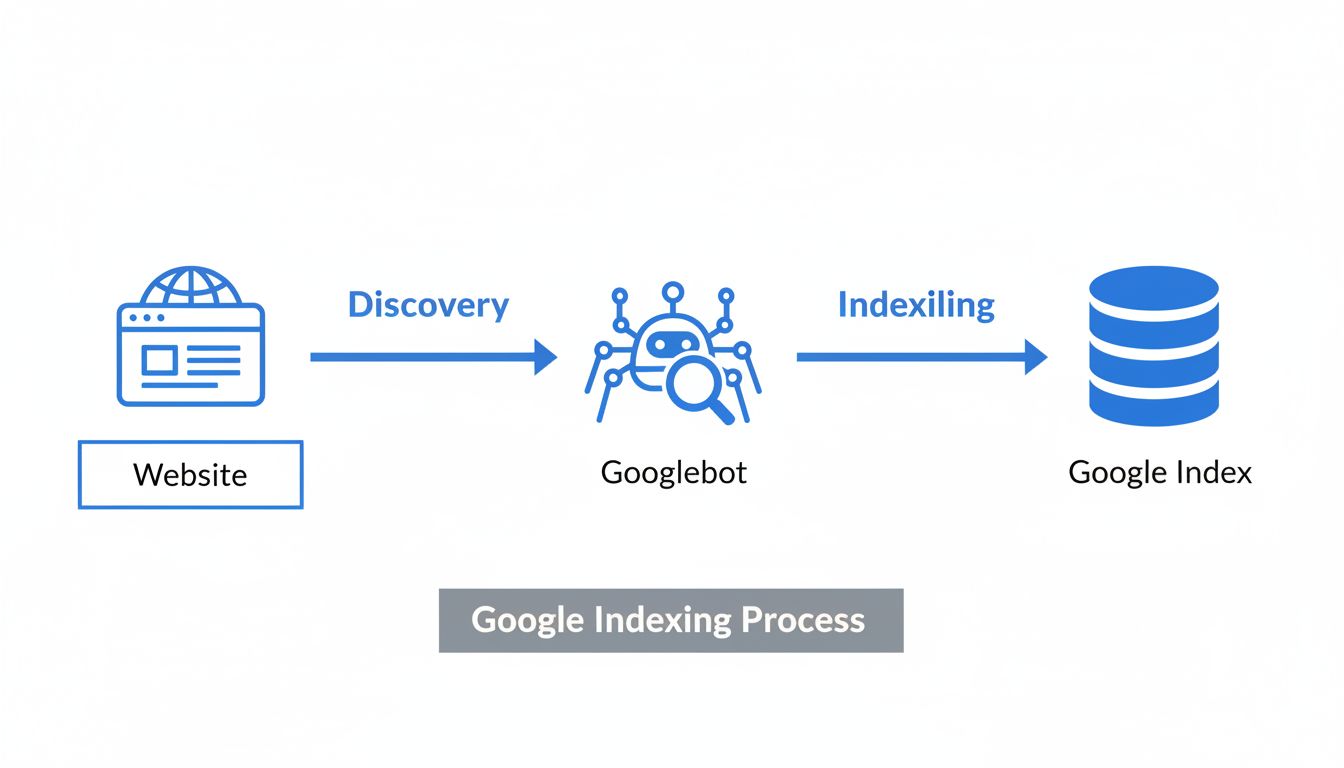
Wenn eine Seite „nicht indexiert“ ist, bedeutet das, dass die Suchmaschine Google sie nicht in ihre Datenbank aufgenommen hat und sie dadurch in den Suchergebnissen unsichtbar bleibt. Das ist grundsätzlich etwas anderes als eine Seite, die zwar existiert, aber einfach für bestimmte Keywords schlecht rankt. Den Unterschied zwischen Indexierung und Ranking zu verstehen, ist für alle, die Online-Inhalte verwalten oder Affiliate-Marketing-Kampagnen betreiben, entscheidend. Die Indexierung ist der notwendige erste Schritt, bevor eine Seite überhaupt in den Suchergebnissen erscheinen kann. Ohne Indexierung ist Ihr Inhalt für Suchmaschinen und potenzielle Besucher, die auf Google angewiesen sind, praktisch unsichtbar. Der Indexierungsprozess umfasst drei entscheidende Phasen: Crawling (wenn der Googlebot Ihre Seite besucht), Indexierung (wenn die Seite in die Google-Datenbank aufgenommen wird) und Ranking (wenn die Seite in den Suchergebnissen für relevante Suchanfragen erscheint).
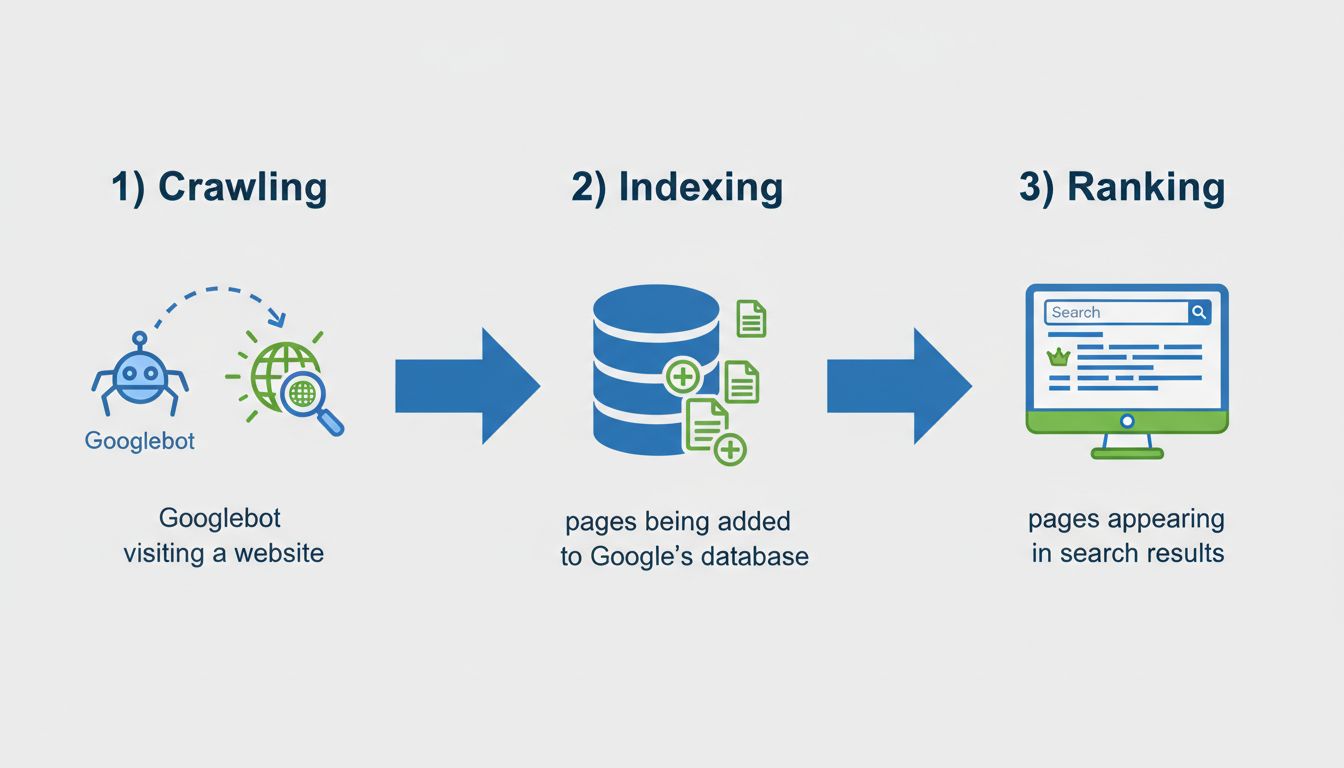
Es gibt zahlreiche Gründe, warum eine Seite nicht indexiert wird – diese lassen sich in drei Hauptkategorien einteilen: technische Probleme, Probleme mit der Inhaltsqualität und Entdeckungsprobleme. Wenn Sie jede Kategorie verstehen, können Sie Indexierungsprobleme gezielter diagnostizieren und beheben. Die häufigsten technischen Barrieren sind Noindex-Meta-Tags, Einschränkungen durch robots.txt, Konflikte mit Canonical-Tags und Serverfehler. Inhaltsbezogene Probleme betreffen meist dünne oder doppelte Inhalte, mangelhafte Qualität oder Inhalte, die nicht zur Suchintention passen. Entdeckungsprobleme treten auf, wenn Google Ihre Seite noch nicht gefunden hat – etwa aufgrund fehlender interner Links, nicht eingetragener Sitemaps oder weil die Seite zu neu ist.
Noindex-Meta-Tags und robots.txt-Sperren
Einer der häufigsten Gründe für nicht indexierte Seiten ist das Vorhandensein eines Noindex-Meta-Tags. Diese HTML-Anweisung sagt Suchmaschinen ausdrücklich, dass die Seite nicht indexiert werden soll, selbst wenn sie erfolgreich gecrawlt werden kann. Das Tag erscheint im Quellcode der Seite als <meta name="robots" content="noindex">. Manchmal werden diese Tags versehentlich während der Entwicklung oder durch falsch konfigurierte SEO-Plugins hinzugefügt. Um zu überprüfen, ob Ihre Seite ein Noindex-Tag hat, klicken Sie mit der rechten Maustaste auf die Seite, wählen Sie „Seitenquelltext anzeigen“ und suchen Sie nach „noindex“. Sie können auch das URL-Prüftool in der Google Search Console verwenden, das klar anzeigt, ob eine Seite durch ein Noindex-Tag blockiert ist.
Die robots.txt-Datei ist eine weitere kritische technische Barriere. Diese Datei steuert, welche Bereiche Ihrer Website vom Googlebot gecrawlt werden dürfen. Wenn wichtige Seiten in der robots.txt mit einer „Disallow“-Anweisung gesperrt sind, kann Google sie nicht crawlen und folglich auch nicht indexieren. Sie können Ihre robots.txt-Datei prüfen, indem Sie yourdomain.com/robots.txt in Ihrem Browser aufrufen. Achten Sie auf Zeilen, die mit „Disallow“ beginnen, und stellen Sie sicher, dass wichtige Bereiche wie /blog/ oder /products/ nicht versehentlich gesperrt sind.
Fehlkonfigurationen bei Canonical-Tags
Canonical-Tags teilen Google mit, welche Version einer Seite indexiert werden soll, wenn Duplikate existieren. Wenn ein Canonical-Tag auf die falsche URL verweist – zum Beispiel auf die Startseite oder eine ganz andere Seite – kann es sein, dass Google die gewünschte Seite ignoriert. Jede Seite sollte idealerweise ein selbstreferenziertes Canonical-Tag besitzen, das auf sich selbst verweist. Sie können dies überprüfen, indem Sie den Quelltext der Seite ansehen und nach link rel="canonical" suchen. Stimmt die URL im Canonical-Tag nicht mit Ihrer aktuellen Seiten-URL überein, liegt hier das Problem.
Serverfehler und HTTP-Statuscodes
Wenn der Googlebot beim Crawlen einer Seite auf Serverfehler (5xx-Statuscodes) oder Fehler „Seite nicht gefunden“ (404-Statuscodes) trifft, interpretiert er dies als Signal, dass die Seite nicht verfügbar oder funktionsfähig ist. Bestehen diese Fehler über längere Zeit, kann Google die Seite vollständig aus dem Index entfernen. Sie können die Crawling-Fehler Ihrer Website in der Google Search Console im Bericht „Abdeckung“ überprüfen, der Seiten mit problematischen HTTP-Statuscodes zeigt.
Dünner und minderwertiger Inhalt
Google legt zunehmend Wert auf die Qualität und Relevanz von Inhalten. Seiten mit dünnem Inhalt – das bedeutet, sie bieten zu wenig Tiefe, Details oder Mehrwert – werden oft aus dem Index ausgeschlossen. Dazu gehören Seiten mit sehr wenig Text, generischen Informationen oder Inhalten, die Nutzeranfragen nicht ausreichend beantworten. Die Algorithmen von Google bewerten, ob Inhalte echten Mehrwert für Suchende bieten. Wenn eine Seite veraltete Informationen enthält, keine eigenen Erkenntnisse liefert oder nur bereits woanders verfügbare Inhalte wiederholt, kann Google entscheiden, dass sie nicht indexiert werden soll.
Probleme mit doppeltem Inhalt
Wenn mehrere Seiten Ihrer Website identische oder nahezu identische Inhalte enthalten, indexiert Google in der Regel nur eine Version und kennzeichnet die anderen als Duplikate. Dies kommt häufig bei von Herstellern übernommenen Produktbeschreibungen, Blogposts mit minimalen Variationen oder für verschiedene Standorte wiederholten Serviceseiten vor. Doppelte Inhalte verschwenden zudem Ihr Crawling-Budget, da der Googlebot Ressourcen dafür aufwenden muss, diese Duplikate zu erkennen, anstatt neue, einzigartige Inhalte zu crawlen.
Nicht zur Suchintention passende Inhalte
Seiten, die nicht zur Suchintention der Nutzer passen, werden häufig von der Indexierung ausgeschlossen. Wenn Sie beispielsweise eine Seite zum Thema „SEO-Tools“ erstellen, diese aber eigentlich ein Blogbeitrag statt eines Tool-Vergleichs ist (was die meisten Suchenden erwarten), kann Google feststellen, dass die Seite für diese Suchanfrage nicht relevant ist und sie nicht indexieren. Die Suchintention zu verstehen, indem man die Top-Ergebnisse analysiert, ist vor der Inhaltserstellung essenziell.
Verwaiste Seiten und interne Verlinkung
Seiten ohne interne Links, die auf sie verweisen, werden als „verwaiste Seiten“ bezeichnet. Wenn eine Seite nirgendwo auf Ihrer Website verlinkt ist und auch nicht in Ihrer Sitemap steht, findet Google sie möglicherweise nie. Selbst wenn Google sie entdeckt, signalisiert der Mangel an internen Links, dass die Seite nicht wichtig ist – was dazu führen kann, dass sie nicht indexiert wird. Interne Links dienen als Pfade für den Googlebot zur Entdeckung von Inhalten und übertragen außerdem Autoritäts- und Relevanzsignale.
Fehlende Sitemap-Einträge
Eine Sitemap ist eine Datei, die die wichtigsten Seiten Ihrer Website auflistet und Google bei der Entdeckung und Priorisierung für das Crawling unterstützt. Fehlt eine Seite in Ihrer Sitemap, ist es für Google schwieriger, sie zu finden – insbesondere, wenn auch interne Links fehlen. Seiten können zwar auch ohne Sitemap indexiert werden, die Aufnahme verbessert die Auffindbarkeit jedoch erheblich.
Einschränkungen beim Crawling-Budget
Größere Websites verfügen über ein begrenztes „Crawling-Budget“ – das ist die Anzahl von Seiten, die Google innerhalb eines bestimmten Zeitraums crawlt. Wenn Ihre Website viele minderwertige Seiten, langsame Ladezeiten oder übermäßige doppelte Inhalte aufweist, kann Google weniger Ressourcen für das Crawlen bereitstellen. Das bedeutet, dass einige Seiten möglicherweise nicht zeitnah oder gar nicht gecrawlt und indexiert werden.
Richten Sie erweitertes Tracking in wenigen Minuten ein. Keine Kreditkarte erforderlich.
Die Google Search Console ist das wichtigste Werkzeug, um herauszufinden, warum Seiten nicht indexiert sind. Die Plattform bietet detaillierte Berichte, die genau zeigen, welche Seiten indexiert sind und warum andere nicht. Um diese Informationen aufzurufen, navigieren Sie zu Ihrer Search-Console-Property, klicken Sie im linken Menü auf „Indexierung“ und wählen Sie dann „Seiten“. Dieser Bericht zeigt Ihre indexierten Seiten und bietet eine Aufschlüsselung der nicht indexierten Seiten nach Grund.
| Fehlertyp | Status in GSC | Bedeutung | Lösung |
|---|---|---|---|
| Noindex-Tag | Ausgeschlossen durch ’noindex’-Tag | Seite hat Noindex-Anweisung | Noindex-Tag von der Seite entfernen |
| robots.txt-Sperre | Blockiert durch robots.txt | Seite in robots.txt gesperrt | robots.txt anpassen, um Crawling zu erlauben |
| Doppelter Inhalt | Duplikat ohne vom Nutzer gewählte kanonische URL | Mehrere ähnliche Seiten vorhanden | Canonical-Tags setzen oder Inhalte zusammenführen |
| Minderwertige Qualität | Gefunden – zurzeit nicht indexiert | Seite als wenig wertvoll eingestuft | Inhaltstiefe und -qualität verbessern |
| Nicht entdeckt | Gefunden – zurzeit nicht indexiert | Seite wurde noch nicht gecrawlt | Interne Links hinzufügen und Sitemap einreichen |
| Serverfehler | Crawling-Anomalie | Server hat Fehler zurückgegeben | Serverprobleme beheben und neu einreichen |
Das URL-Prüftool ist eine weitere leistungsstarke Funktion. Fügen Sie einfach eine bestimmte URL in die Suchleiste oben in der Search Console ein, und Google zeigt Ihnen, ob diese Seite indexiert ist, wann sie zuletzt gecrawlt wurde und welche Probleme die Indexierung verhindern. Wenn eine Seite nicht indexiert ist, erklärt das Tool den Grund und bietet oft einen Button „Indexierung beantragen“, mit dem Sie Google auffordern können, die Seite erneut zu crawlen.
Technische Hindernisse beseitigen
Beginnen Sie mit der Behebung technischer Probleme. Wenn Ihre Seite ein Noindex-Tag hat und Sie möchten, dass sie indexiert wird, entfernen Sie das Tag aus dem HTML der Seite. In WordPress geschieht dies typischerweise über Ihr SEO-Plugin (Yoast, Rank Math, All in One SEO), indem Sie die Option „Suchmaschinen dürfen diese Seite indexieren“ aktivieren. Ist die Seite in der robots.txt gesperrt, passen Sie Ihre robots.txt-Datei an, damit dieser Bereich gecrawlt werden darf. Bei Problemen mit Canonical-Tags stellen Sie sicher, dass jede Seite ein selbstreferenziertes Canonical-Tag besitzt.
Inhaltsqualität verbessern
Wenn Ihre Seite als „Gefunden – zurzeit nicht indexiert“ oder „Gecrawlt – zurzeit nicht indexiert“ markiert ist, liegt das Problem wahrscheinlich an der Qualität des Inhalts. Erweitern Sie Ihren Inhalt, um umfassendere Informationen zu bieten, fügen Sie eigene Erkenntnisse oder Daten hinzu, passen Sie ihn an die Suchintention an und entfernen Sie doppelte Inhalte. Ihre Seite sollte die Fragen der Nutzer zu den relevanten Suchbegriffen wirklich beantworten.
Interne Verlinkung optimieren
Fügen Sie interne Links von relevanten Seiten Ihrer Website zur nicht indexierten Seite hinzu. Diese Links sollten beschreibende Ankertexte verwenden und natürlich im Inhalt platziert sein. Ziel sind 2-5 interne Links pro Seite. Stellen Sie außerdem sicher, dass die Seite in Ihrer XML-Sitemap enthalten und die Sitemap in der Google Search Console eingereicht ist.
Zur Indexierung einreichen
Nach den Korrekturen verwenden Sie das URL-Prüftool in der Google Search Console, um die Indexierung anzufordern. Google wird die Seite erneut crawlen und bewerten, ob sie indexiert werden sollte. Es gibt keine garantierte Zeitspanne, aber in der Regel werden Seiten innerhalb weniger Tage bis zu einigen Wochen erneut gecrawlt.
Erfahren Sie als Erster von neuen Funktionen und Produkt-Updates.
Um eine gute Indexierung zu gewährleisten, ist ständige Aufmerksamkeit erforderlich. Überprüfen Sie Ihre Website regelmäßig mit der Google Search Console, um den Indexierungsstatus zu überwachen. Stellen Sie sicher, dass Ihre robots.txt-Datei korrekt konfiguriert ist und keine wichtigen Inhalte versehentlich blockiert. Implementieren Sie auf Ihrer gesamten Website korrekte Canonical-Tags, insbesondere wenn Sie mehrere Versionen ähnlicher Inhalte haben. Pflegen Sie eine konsistente interne Verlinkung und verbinden Sie zusammengehörige Inhalte, damit Google Ihre Seitenstruktur versteht. Und schließlich: Konzentrieren Sie sich auf die Erstellung hochwertiger, origineller Inhalte, die Ihrer Zielgruppe echten Mehrwert bieten. Das ist die effektivste langfristige Strategie, um sicherzustellen, dass Ihre Seiten indexiert und gerankt werden.
Verfolgen und verwalten Sie Ihre Affiliate-Kampagnen effektiv mit den fortschrittlichen Tracking- und Analysefunktionen von PostAffiliatePro. Stellen Sie sicher, dass Ihre Inhalte die richtige Zielgruppe erreichen und maximieren Sie Ihre Affiliate-Einnahmen mit unserer branchenführenden Plattform.
Erfahren Sie 7 bewährte Methoden, um zu überprüfen, ob Ihre Website von Google indexiert wurde. Nutzen Sie die Google Search Console, Site-Operatoren, URL-Inspe...
Indexierung ist ein Prozess, bei dem eine bestimmte Webseite von Crawlern gefunden wird. Wichtige Signale werden erkannt und alle Daten werden im Index erfasst.
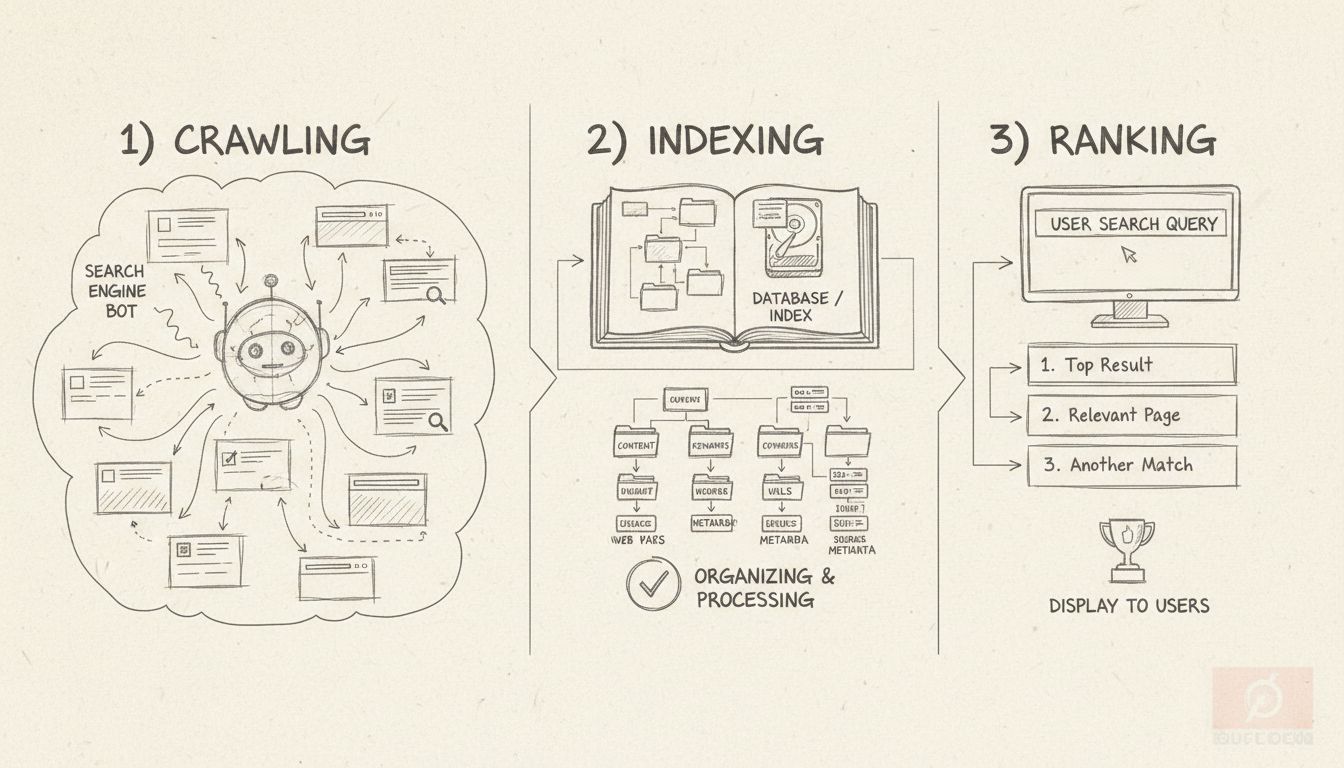
Erfahren Sie, was SEO-Indexierung bedeutet, wie sie funktioniert und warum sie entscheidend für die Sichtbarkeit Ihrer Website in der Suche ist. Entdecken Sie B...
Treten Sie unserer Gemeinschaft zufriedener Kunden bei und bieten Sie exzellenten Kundensupport mit Post Affiliate Pro.
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.