Ist Duplicate Content schlecht für SEO? Vollständiger Leitfaden zu den Auswirkungen von Duplicate Content
Erfahren Sie, warum Duplicate Content der SEO schadet, wie er das Ranking beeinflusst und bewährte Lösungen wie Canonical-Tags und 301-Weiterleitungen, um Duplicate-Content-Probleme im Jahr 2025 zu beheben.
Ist Duplicate Content schlecht für SEO?
Ja, Duplicate Content kann sich negativ auf die SEO auswirken, da Suchmaschinen verwirrt werden, welche Version sie ranken sollen, Linkkraft auf mehrere URLs verteilt wird, das Crawl-Budget verschwendet wird und ggf. kopierte Inhalte Ihre Originalseiten übertreffen. Obwohl Google keine explizite Duplicate-Content-Strafe hat, können die indirekten Auswirkungen Ihre Sichtbarkeit und den organischen Traffic erheblich beeinträchtigen.
Duplicate Content und seine Auswirkungen auf SEO verstehen
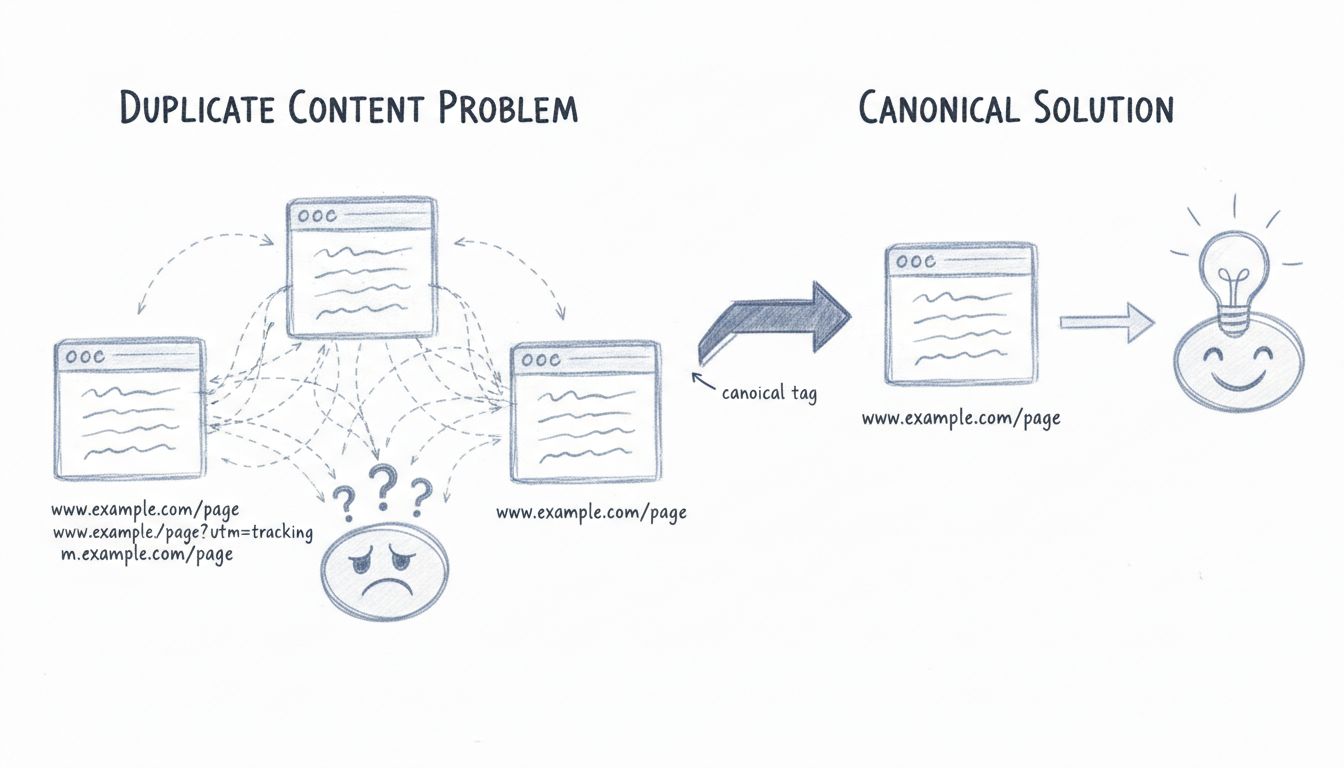
Als Duplicate Content werden identische oder weitgehend ähnliche Inhalte bezeichnet, die im Internet unter mehreren URLs erscheinen. Dies kann innerhalb einer einzelnen Website oder über verschiedene Domains hinweg vorkommen. Laut aktuellen Daten bestehen etwa 25–30 % des Webs aus Duplicate Content, was es zu einer der häufigsten technischen SEO-Herausforderungen für Website-Betreiber macht. Wenn Suchmaschinen auf mehrere Versionen desselben Inhalts stoßen, müssen sie entscheiden, welche Version die maßgebliche Quelle ist, welche sie indexieren und welche sie in den Suchergebnissen ranken. Dieser Entscheidungsprozess führt zu mehreren Komplikationen, die die Sichtbarkeit Ihrer Website in Suchmaschinen und die Performance beim organischen Traffic negativ beeinflussen können.
Die Verwirrung, die Duplicate Content bei Suchmaschinen stiftet, ist grundsätzlich anders als eine direkte Abstrafung. Google hat mehrfach ausdrücklich erklärt, dass es keine direkte Duplicate-Content-Strafe gibt. Das bedeutet jedoch nicht, dass Duplicate Content harmlos ist. Die indirekten Auswirkungen von Duplicate Content können für Ihre SEO-Performance genauso schädlich sein wie eine direkte Strafe. Diese Effekte zu verstehen, ist entscheidend, um eine gesunde, gut optimierte Website zu betreiben, die in den Suchergebnissen erfolgreich ist.
Wie Duplicate Content Suchmaschinen verwirrt
Suchmaschinen wie Google nutzen ausgefeilte Algorithmen, um zu bestimmen, welche Version von Duplicate Content indexiert und gerankt werden soll. Existieren mehrere Varianten desselben Inhalts, müssen Suchmaschinen diese Seiten zu einem sogenannten „Duplicate Cluster“ zusammenfassen. Aus diesem Cluster wählt Google die URL aus, die nach ihrer Einschätzung am besten den Inhalt in den Suchergebnissen repräsentiert. Dieser Prozess, bekannt als Kanonisierung (Canonicalization), soll Linkkraft und Ranking-Power auf eine einzelne URL bündeln.
Allerdings funktioniert dieser automatische Prozess nicht immer perfekt. Suchmaschinen können die falsche Version als kanonische URL auswählen, was dazu führt, dass unerwünschte oder unfreundliche URLs in den Suchergebnissen erscheinen. Wenn beispielsweise Ihre Website denselben Inhalt sowohl unter example.com/page/ als auch unter example.com/page?utm_source=newsletter bereitstellt, könnte Google die Version mit Tracking-Parametern statt der sauberen, benutzerfreundlichen Version ranken. Sehen Nutzer diese unfreundlichen URLs in den Suchergebnissen, sind sie weniger geneigt, darauf zu klicken – was zu geringeren Klickraten und weniger organischem Traffic führen kann, selbst wenn Ihre Seite eigentlich gut rankt.
Starten Sie noch heute Ihr Affiliate-Programm
Richten Sie erweitertes Tracking in wenigen Minuten ein. Keine Kreditkarte erforderlich.
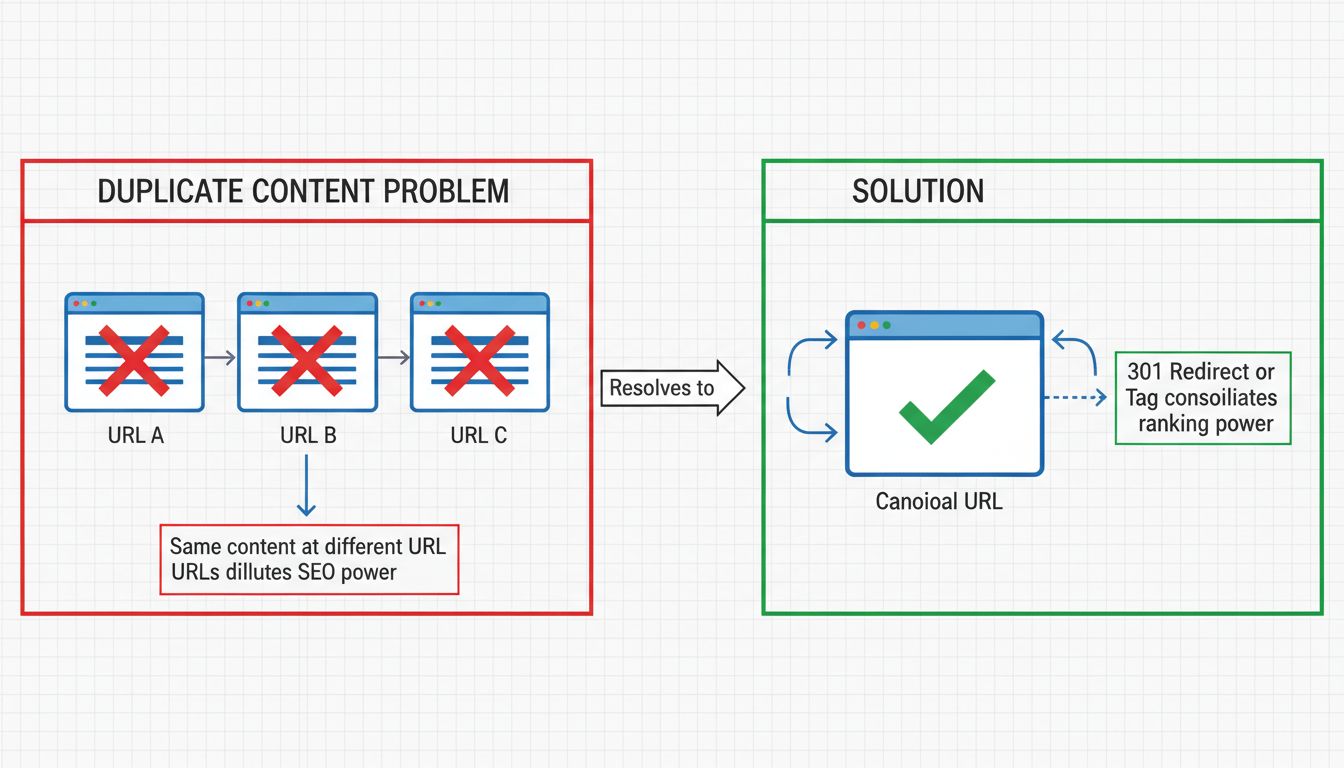
Eine der gravierendsten Auswirkungen von Duplicate Content auf die SEO ist die Verdünnung der Linkkraft (Link Equity). Wenn derselbe Inhalt unter mehreren URLs existiert, können Backlinks von anderen Websites auf verschiedene Versionen verweisen. Anstatt dass die gesamte Linkkraft auf eine maßgebliche Seite fließt, wird sie auf mehrere Duplicate-URLs verteilt. Diese Fragmentierung schwächt das gesamte Autoritätssignal, das Suchmaschinen für das Ranking heranziehen.
Ein Beispiel aus der Praxis: Ist Ihr Inhalt sowohl unter buffer.com/library/social-media-manager-checklist als auch unter buffer.com/resources/social-media-manager-checklist erreichbar, könnten externe Websites auf beide Versionen verlinken. Eine URL sammelt dann vielleicht 106 verweisende Domains, die andere 144. Auch wenn Googles Kanonisierung diese Links theoretisch zusammenführen sollte, ranken in der Praxis oft beide URLs separat – die Linkkraft wird also nicht vollständig gebündelt. Das Ergebnis: zwei mittelmäßig starke Seiten statt einer sehr autoritativen, die noch besser ranken und mehr Suchtraffic erzielen könnte.
Verschwendung des Crawl-Budgets und Verzögerungen beim Indexieren
Suchmaschinen weisen jeder Website ein begrenztes Crawl-Budget zu – das ist die Anzahl an Seiten, die sie in einem bestimmten Zeitraum crawlen und indexieren. Enthält Ihre Website viele Duplicate-Content-Seiten, verschwenden Suchmaschinen dieses wertvolle Crawl-Budget damit, Duplikate zu crawlen und erneut zu crawlen, statt neue oder aktualisierte Inhalte zu entdecken. Besonders problematisch ist das für Websites mit langsamen Serverreaktionen oder begrenzter Bandbreite, denn Googles Crawling-Rate ist bei schnelleren Websites höher.
Wird das Crawl-Budget für Duplikate verschwendet, kann das dazu führen, dass neue Seiten langsamer indexiert und aktualisierte Seiten später neu erfasst werden. Das bedeutet, dass frische Inhalte möglicherweise erst verzögert in den Suchergebnissen erscheinen und Aktualisierungen bestehender Seiten nicht so schnell von Google erfasst werden, wie sie sollten. Für inhaltsstarke oder häufig publizierende Websites kann diese Verzögerung zu erheblichen verlorenen Chancen beim organischen Traffic und der Suchsichtbarkeit führen.
Newsletter abonnieren
Erfahren Sie als Erster von neuen Funktionen und Produkt-Updates.
Häufige Ursachen von Duplicate Content
Ursache
Beschreibung
Lösung
URL-Parameter
Tracking-Parameter (UTM-Codes), Session-IDs und Filter erzeugen mehrere URLs mit identischem Inhalt
Canonical-Tags oder 301-Weiterleitungen auf saubere URLs setzen
HTTPS vs. HTTP
Inhalt ist sowohl unter sicherer als auch unsicherer Version erreichbar
Server so konfigurieren, dass alle Zugriffe auf die HTTPS-Version umgeleitet werden
Bevorzugte Domain in der Google Search Console festlegen und Weiterleitungen nutzen
Trailing Slashes
URLs mit und ohne abschließenden Slash werden als separate Seiten behandelt
Konsistente Weiterleitungen implementieren (z. B. immer mit Slash)
Mobile-Versionen
Separate mobile URLs (m.example.com) mit identischem Inhalt
rel=“alternate”-Tags verwenden oder auf Responsive Design setzen
AMP-Seiten
Accelerated Mobile Pages erzeugen Duplikate
AMP-Seiten auf die Nicht-AMP-Versionen kanonisieren
Druckoptimierte URLs
Druckversionen von Seiten mit gleichem Inhalt
Druckversionen auf Originalseiten kanonisieren
Tag-/Kategorie-Seiten
Mehrere Tag-Seiten mit identischem Inhalt, wenn nur ein Artikel dieses Tag nutzt
Niedrigwertige Tag-Seiten auf noindex setzen oder Tags konsolidieren
Paginierung
Kommentar- oder Produktpaginierung erzeugt viele ähnliche Seiten
rel=“prev” und rel=“next” nutzen oder paginierte Seiten auf noindex setzen
Staging-Umgebungen
Entwicklungs-/Staging-Seiten werden von Suchmaschinen indexiert
Staging mit robots.txt, noindex oder Authentifizierung schützen
Verhindern, dass kopierte Inhalte Sie überholen
Duplicate-Content-Probleme innerhalb der eigenen Website sind häufig, aber auch externer Duplicate Content kann Ihrer SEO schaden. Wenn andere Websites Ihre Inhalte scrapen oder ohne Erlaubnis erneut veröffentlichen, entstehen Duplikate über verschiedene Domains hinweg. In seltenen Fällen kann Google, falls die scrappende Website eine höhere Domain-Autorität hat, deren Version als Original einstufen und höher ranken als Ihren authentischen Inhalt. Besonders für neue oder kleinere Websites im Wettbewerb mit etablierten Domains ist das problematisch.
Schützen Sie sich, indem Sie auf allen Seiten selbstreferenzierende Canonical-Tags einfügen. Ein solches Canonical-Tag verweist auf die eigene Seite und signalisiert Suchmaschinen, dass dies die maßgebliche Version ist. Zwar übernehmen nicht alle Scraper Ihren HTML-Code, doch diejenigen, die es tun, sehen Ihr Canonical-Tag und erkennen Sie als Quelle an. Wenn Sie Inhalte absichtlich auf anderen Websites syndizieren, sollten Sie immer verlangen, dass ein Canonical-Link auf Ihre Originalseite gesetzt wird. So stellen Sie sicher, dass trotz mehrfacher Veröffentlichungen der gesamte SEO-Wert auf Ihre Seite zurückfließt.
Technische Lösungen zur Behebung von Duplicate Content
Canonical-Tags implementieren
Das Canonical-Tag ist eine der effektivsten und am weitesten verbreiteten Lösungen für Duplicate Content. Dieses HTML-Element teilt Suchmaschinen mit, welche Version einer Seite als maßgebliche Quelle behandelt werden soll. Das Canonical-Tag wird im <head> Ihrer HTML-Seite platziert und sieht so aus:
Fügen Sie dieses Tag auf Duplikat-Seiten ein und verweisen Sie auf die kanonische (Original-)Version, bündeln Suchmaschinen Ranking-Power und Linkkraft auf diese einzelne URL. Das Canonical-Tag überträgt etwa so viel Linkkraft wie eine 301-Weiterleitung, lässt sich aber oft leichter umsetzen, da keine Server-Konfiguration nötig ist. Besonders bei Duplicate Content durch URL-Parameter, Mobile-Versionen und AMP-Seiten ist es sehr hilfreich.
301-Weiterleitungen nutzen
Eine 301-Weiterleitung ist eine permanente Weiterleitung, die sowohl Nutzer als auch Suchmaschinen mitteilt, dass eine Seite dauerhaft an eine neue Adresse umgezogen ist. Durch 301-Weiterleitungen von Duplicate-URLs auf die kanonische Version bündeln Sie Ranking-Power und Linkkraft auf die Ziel-URL. Diese Lösung eignet sich besonders, wenn Sie Duplicate-URLs komplett von Ihrer Website entfernen möchten.
Ist Ihre Website z. B. sowohl unter http://example.com als auch unter https://www.example.com erreichbar, sollten Sie 301-Weiterleitungen so einrichten, dass aller Traffic und alle Suchmaschinen auf Ihre bevorzugte Version umgeleitet werden. So stellen Sie sicher, dass Suchmaschinen nur eine Version indexieren und Duplicate Content gänzlich vermieden wird. Die 301-Weiterleitung überträgt nahezu 100 % der Linkkraft an die Zielseite und ist daher eine ausgezeichnete Wahl zur Konsolidierung von Duplicate Content.
Meta Robots Noindex-Tag
Das Meta-Robots-noindex-Tag eignet sich besonders, um Duplicate Content, den Sie für Nutzer zugänglich lassen, aber nicht von Suchmaschinen indexieren lassen möchten, zu steuern. Durch das Hinzufügen von <meta name="robots" content="noindex,follow"> in den <head>-Bereich einer Seite teilen Sie Suchmaschinen mit, dass diese Seite nicht indexiert werden soll, Links darauf aber weiterhin verfolgt werden dürfen.
Diese Lösung ist ideal bei Duplicate Content durch Paginierung, Tag-Seiten, Filterseiten und andere automatisch generierte Seiten ohne Mehrwert. Wichtig: Google crawlt diese Seiten weiterhin, um Ihre Noindex-Anweisung zu bestätigen – Sie sollten sie also nicht zusätzlich per robots.txt blockieren. Das Noindex-Tag ist weniger effektiv als Canonical-Tags oder 301-Weiterleitungen, wenn es um die Bündelung von Linkkraft geht, eignet sich aber hervorragend, um Duplicate-Seiten mit geringem Wert aus den Suchergebnissen fernzuhalten.
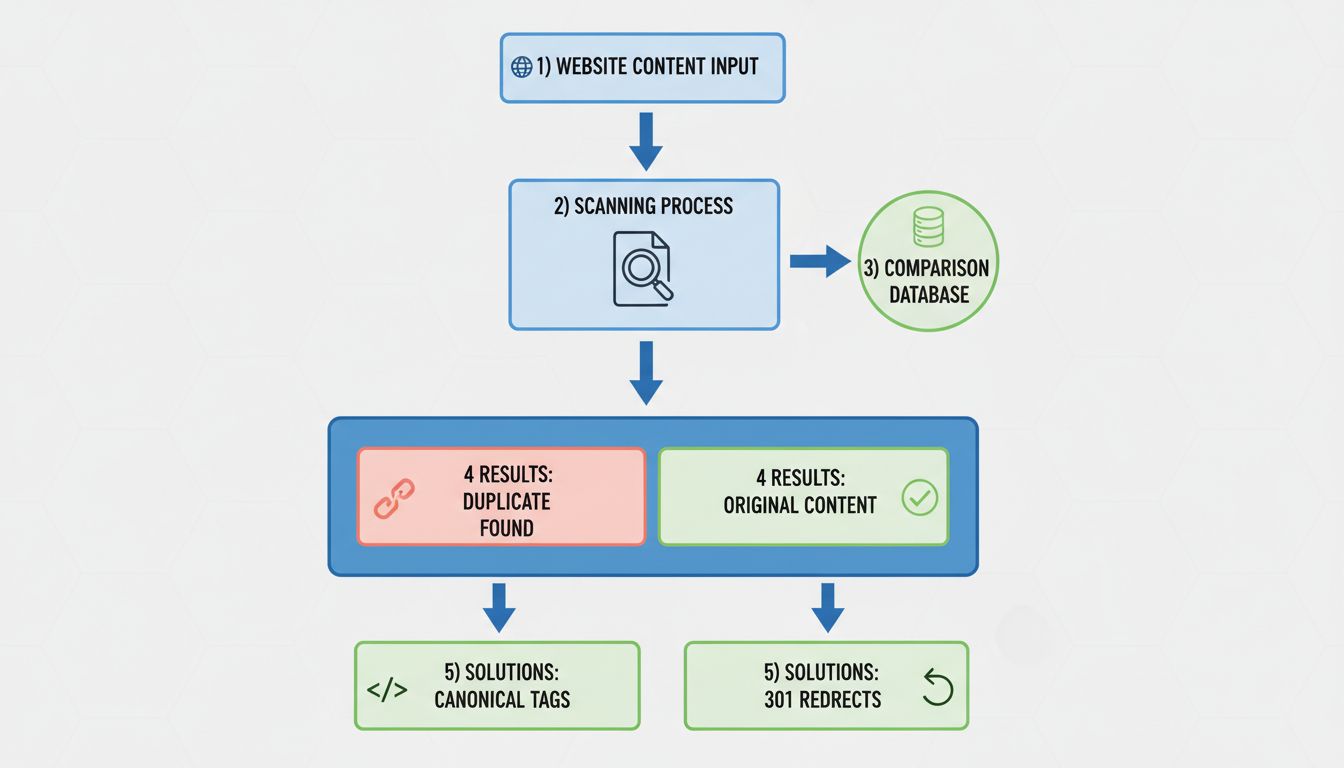
Duplicate Content auf Ihrer Website erkennen
Um Duplicate-Content-Probleme zu identifizieren, sollten Sie regelmäßig umfassende Site-Audits mit Spezialtools für SEO durchführen. Diese Tools crawlen Ihre gesamte Website und erkennen Seiten mit identischem oder nahezu identischem Inhalt. Überprüfen Sie die Ergebnisse auf Cluster von Duplicate-Seiten ohne korrekte Canonical-Tags – sie werden als zu behebende Probleme markiert.
Auch die Google Search Console liefert wichtige Hinweise zu Duplicate Content. Der Bericht zur Indexabdeckung zeigt, welche Seiten Google indexiert hat, und kennzeichnet Probleme wie „Duplikat ohne vom Nutzer ausgewähltes Canonical“ oder „Duplikat, Google hat ein anderes Canonical gewählt als der Nutzer“. Solche Hinweise deuten darauf hin, dass Google Duplicate Content auf Ihrer Website erkannt hat und ggf. nicht wie von Ihnen beabsichtigt damit umgeht. Mit dem URL-Prüftool in der Google Search Console können Sie prüfen, wie Google einzelne URLs behandelt – ob sie indexiert, kanonisiert oder vom Index ausgeschlossen sind.
Best Practices zur Vermeidung von Duplicate Content
Duplicate Content zu verhindern ist viel einfacher, als ihn nachträglich zu beheben. Legen Sie klare URL-Standards für Ihre Website fest und achten Sie auf Konsistenz in der gesamten Seitenstruktur. Verlinken Sie intern immer auf dieselbe URL-Version – vermeiden Sie Mischformen aus www und non-www sowie wechselnde Nutzung von Trailing Slashes. Diese Konsistenz hilft Suchmaschinen, Ihre bevorzugte URL-Struktur zu erkennen.
Für E-Commerce-Websites mit Facettennavigation, Filtern und Sortierungen sollten Sie Parameter richtig handhaben, um die Entstehung hunderter Duplicate-Seiten zu vermeiden. Nutzen Sie Canonical-Tags, um gefilterte Ansichten auf die Basis-Produktseite zurückzuführen, oder verwenden Sie das Parameter-Tool der Google Search Console, um Google anzuweisen, bestimmte Parameter beim Crawlen zu ignorieren.
Setzen Sie bei Content-Management-Systemen wie WordPress Funktionen außer Kraft, die automatisch Duplicate Content erzeugen – etwa eigene Seiten für Bildanhänge oder paginierte Kommentare. Die meisten modernen CMS bieten Einstellungen dafür. Schützen Sie außerdem Ihre Staging- und Entwicklungsumgebungen vor der Indexierung, indem Sie robots.txt, Noindex-Meta-Tags oder HTTP-Authentifizierung einsetzen, damit Suchmaschinen diese Duplikate nicht crawlen.
Fazit zu Duplicate Content und SEO
Auch wenn Google keine spezifische Duplicate-Content-Strafe verhängt, können die indirekten Auswirkungen von Duplicate Content Ihre SEO-Performance erheblich beeinträchtigen. Duplicate Content verwirrt Suchmaschinen bei der Auswahl der Ranking-Version, verteilt Linkkraft auf mehrere URLs, verschwendet Ihr Crawl-Budget und kann dazu führen, dass kopierte Inhalte Ihre Originalseiten übertreffen. Durch Canonical-Tags, 301-Weiterleitungen und eine saubere URL-Struktur können Sie Duplicate-Content-Probleme verhindern und beheben, bevor sie Ihrer Sichtbarkeit schaden.
Der Schlüssel zu einer gesunden Website ist ein proaktives Duplicate-Content-Management. Prüfen Sie Ihre Website regelmäßig auf Duplicate-Content-Probleme, setzen Sie konsequent Kanonisierung ein und halten Sie Ihre URL-Standards einheitlich. So stellen Sie sicher, dass Suchmaschinen Ihre maßgeblichen Inhalte erkennen, Linkkraft auf Ihre bevorzugten URLs bündeln und Ihre Website effizient crawlen und indexieren können. Das Ergebnis: bessere Rankings, mehr organischer Traffic und insgesamt stärkere SEO-Performance für Ihre Website.
Optimieren Sie Ihre Affiliate-Website mit PostAffiliatePro
Verwalten Sie mehrere Affiliate-Programme und verhindern Sie Duplicate-Content-Probleme mit den fortschrittlichen Tracking- und Content-Management-Funktionen von PostAffiliatePro. Sorgen Sie dafür, dass Ihre Affiliate-Marketing-Aktivitäten maximalen SEO-Wert bringen.
So beheben Sie Probleme mit doppeltem Content: Umfassender SEO-Leitfaden
Erfahren Sie bewährte Methoden zur Behebung von Problemen mit doppeltem Content, einschließlich 301-Weiterleitungen, Canonical-Tags und Noindex-Direktiven. Schü...
Erfahren Sie, wie Sie doppelte Inhalte mit Tools wie Copyscape, Siteliner und der Google Search Console überprüfen. Entdecken Sie manuelle Methoden, interne Dup...
Doppelter Inhalt bezeichnet identische oder sehr ähnliche Inhalte, die auf mehreren URLs erscheinen – entweder innerhalb einer einzelnen Website oder auf versch...
5 Min. Lesezeit
SEO
Content
+3
Sie sind in guten Händen!
Treten Sie unserer Gemeinschaft zufriedener Kunden bei und bieten Sie exzellenten Kundensupport mit Post Affiliate Pro.