Warum werden Web-Spider als Computer-Spider bezeichnet? Verständnis von Web-Crawlern
Erfahren Sie, warum Web-Spider als Computer-Spider bezeichnet werden und wie sie das Internet durchsuchen. Entdecken Sie, wie Suchmaschinen-Crawler funktionieren und warum sie für SEO und Affiliate-Marketing wichtig sind.
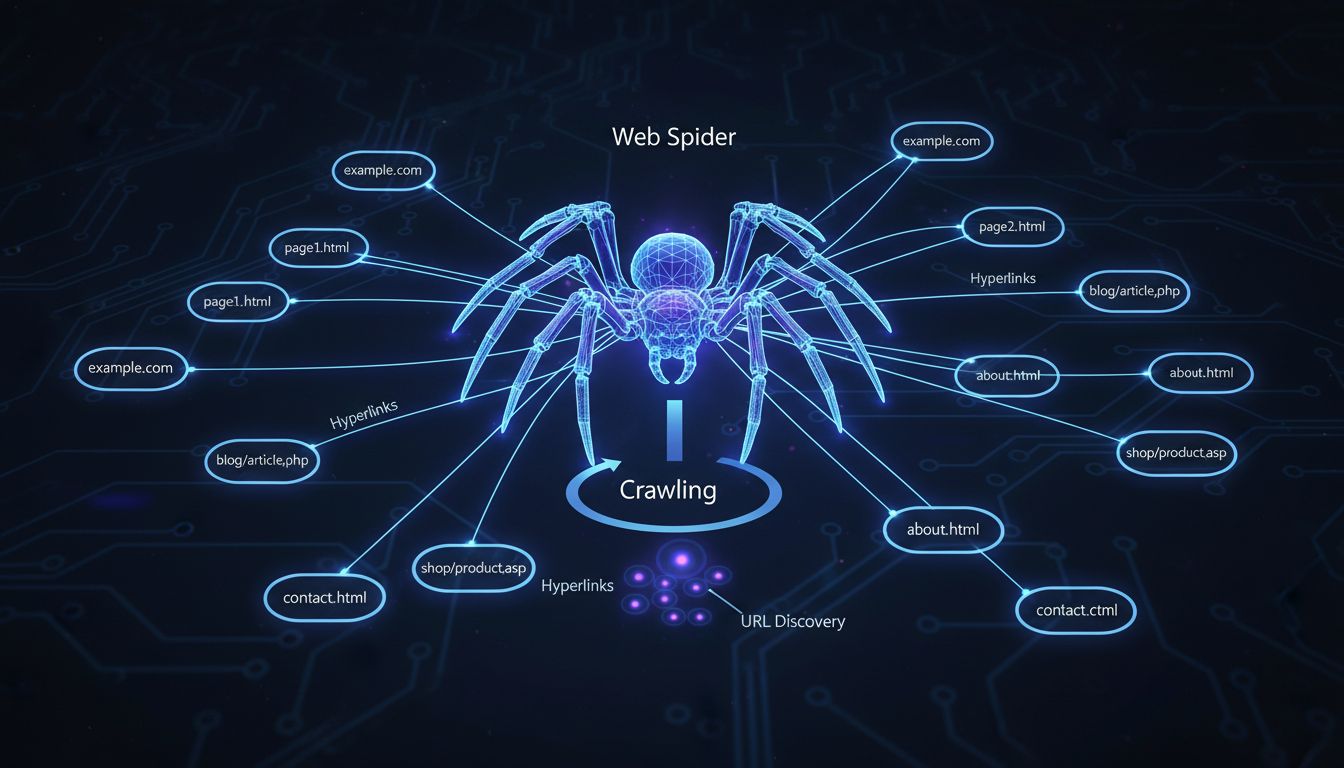
Warum werden sie Computer-Spider genannt? Sie werden Computer-Spider genannt, weil sie das Web "durchkriechen".
Web-Spider werden als Computer-Spider bezeichnet, weil sie das Internet "durchkriechen", indem sie Hyperlinks von einer Seite zur nächsten folgen – ähnlich wie eine Spinne über ihr Netz läuft. Diese automatisierten Programme durchsuchen systematisch Websites, um Inhalte für Suchmaschinen zu entdecken und zu indexieren.
Das Spider-Metapher verstehen
Der Begriff „Computer-Spider“ stammt aus einer treffenden Analogie, die genau beschreibt, wie diese automatisierten Programme im Internet funktionieren. So wie eine echte Spinne sich an Fäden und Verbindungen über ihr Netz bewegt, navigiert ein Web-Spider durch das Internet, indem er Hyperlinks von einer Webseite zur nächsten folgt. Diese Metapher ist so eingängig, dass sie mittlerweile zum Standardbegriff für Webentwickler, SEO-Experten und Digital-Marketer weltweit geworden ist. Der Name fängt das Verhalten des Crawlers auf eine Weise ein, die sowohl für technische als auch nicht-technische Zielgruppen sofort verständlich ist. Wenn Sie dieses Grundkonzept verstanden haben, erkennen Sie, wie elegant die Infrastruktur des Internets natürliche Systeme aus der Natur widerspiegelt.
Wie Web-Spider das Internet durchsuchen
Web-Spider arbeiten nach einem systematischen und methodischen Prozess, der mit einer Startliste bekannter URLs beginnt. Der Crawler besucht zunächst diese Webseiten und untersucht sorgfältig deren Inhalte und Struktur. Während er jede Seite verarbeitet, identifiziert der Spider alle Hyperlinks auf dieser Seite und fügt sie einer Warteschlange von URLs hinzu, die als Nächstes besucht werden sollen. Dieser Vorgang wiederholt sich fortlaufend, sodass der Spider mit jeder Iteration tiefer in das Web vordringt. Im Grunde erstellt der Spider eine Karte des Internets, indem er diesen Verbindungen folgt – ähnlich wie ein Entdecker neues Terrain kartiert, indem er Pfade und Wege folgt. Dieser systematische Ansatz stellt sicher, dass Suchmaschinen täglich Millionen neuer Seiten entdecken und katalogisieren können.
Crawler-Komponente
Funktion
Zweck
URL-Warteschlange
Speichert Liste der zu besuchenden Seiten
Organisiert die Crawl-Reihenfolge
Parser
Liest Seiteninhalt und HTML
Extrahiert Links und Metadaten
Indexer
Speichert Seiteninformationen
Erstellt durchsuchbare Datenbank
Scheduler
Bestimmt die Crawl-Frequenz
Verwalten der Ressourcenverteilung
User-Agent
Identifiziert den Crawler
Kommuniziert mit Servern
Der technische Ablauf hinter dem Web-Crawling
Bevor ein Web-Spider mit seiner Crawl-Operation beginnt, müssen Entwickler klare, vordefinierte Anweisungen festlegen, die das Verhalten des Spiders steuern. Diese Anweisungen bestimmen, welche Seiten gecrawlt werden, wie oft Seiten erneut besucht werden und welche Informationen von jeder Seite extrahiert werden sollen. Der Crawler führt diese Anweisungen dann automatisch aus und folgt dem Algorithmus exakt wie programmiert. Wenn der Spider eine Website besucht, prüft er zunächst die robots.txt-Datei – eine Textdatei, die Regeln für den Zugriff von Crawlern festlegt. Dieses Protokoll, bekannt als Robot Exclusion Protocol, ermöglicht es Website-Betreibern, ihre Präferenzen darüber mitzuteilen, welche Bereiche ihrer Seite gecrawlt werden dürfen und welche nicht. Die vom Crawler gesammelten Informationen hängen vollständig von den ihm gegebenen Anweisungen ab – deshalb ist die Einrichtungsphase entscheidend für den gewünschten Erfolg.
Verschiedene Arten von Web-Spidern
Web-Spider gibt es in verschiedenen Formen, jeweils für spezielle Zwecke und Anwendungen entwickelt. Suchmaschinen-Spider wie der Googlebot sind die bekanntesten Vertreter und werden von großen Suchmaschinen eingesetzt, um Webseiten zu entdecken und für Suchergebnisse zu indexieren. Fokussierte Crawler hingegen beschränken ihren Suchbereich auf bestimmte Themen oder Bereiche des Internets, um detaillierte Indizes von Nischeninhalten zu erstellen. Webanalyse-Spider helfen Website-Betreibern, die eigene Seite zu überwachen, indem sie Kennzahlen wie Seitenbesuche, defekte Links und Seitenleistung erfassen. Preisvergleich-Spider sammeln automatisch Preisinformationen von verschiedenen Anbietern, sodass Vergleichsportale ihren Nutzern aktuelle Marktdaten anbieten können. E-Mail-Validierungs-Spider überprüfen E-Mail-Adressen und prüfen deren Zustellbarkeit. Jeder Spidertyp erfüllt eine spezifische Funktion im digitalen Ökosystem, und das Verständnis dieser Unterschiede hilft Website-Betreibern, ihre Seiten für die passenden Crawler zu optimieren.
Warum Suchmaschinen auf Web-Spider angewiesen sind
Suchmaschinen können ohne Web-Spider nicht funktionieren, denn diese automatisierten Programme sind dafür zuständig, neue Inhalte zu entdecken und Suchindizes aktuell zu halten. Wenn Sie eine Suchanfrage stellen, durchsucht die Suchmaschine nicht das Live-Internet in Echtzeit, sondern einen Index, der von Web-Spidern erstellt wurde, die zuvor Milliarden von Webseiten besucht und katalogisiert haben. Ohne Spider hätten Suchmaschinen keine Möglichkeit festzustellen, welche Inhalte es im Internet gibt oder wie sie für die Suche organisiert werden können. Durch die Fähigkeit des Spiders, Hyperlinks zu folgen, können neue Seiten automatisch entdeckt werden, ohne dass eine manuelle Anmeldung erforderlich ist. Dieser automatisierte Entdeckungsprozess macht das Internet für Milliarden von Nutzern weltweit durchsuchbar und zugänglich. Die Effizienz und Geschwindigkeit von Web-Spidern beeinflussen direkt, wie schnell neue Inhalte in den Suchergebnissen erscheinen.
Die Bedeutung von Web-Spidern für SEO und digitales Marketing
Für Website-Betreiber und Digital-Marketer ist das Verständnis von Web-Spidern essenziell, denn diese Crawler entscheiden darüber, ob Ihre Inhalte in den Suchergebnissen erscheinen. Wenn ein Suchmaschinen-Spider Ihre Website nicht crawlen kann, werden Ihre Seiten nicht indexiert und tauchen ungeachtet ihrer Qualität nicht in den Suchergebnissen auf. Deshalb konzentrieren sich SEO-Experten darauf, Websites „crawlerfreundlich“ zu gestalten – mit einer sauberen Seitenstruktur, schnellen Ladezeiten und klarer Navigation. Besonders Affiliate-Marketer profitieren davon, das Verhalten von Spidern zu verstehen, denn es beeinflusst direkt, wie ihre Affiliate-Seiten entdeckt und gerankt werden. PostAffiliatePro erkennt, dass erfolgreiche Affiliate-Programme von Sichtbarkeit abhängen, und unsere Plattform hilft Ihnen, Ihr Affiliate-Netzwerk so zu optimieren, dass Suchmaschinen-Spider Ihre Affiliate-Inhalte leicht entdecken und indexieren können. Indem Sie Ihre Affiliate-Seiten für Crawler zugänglich machen, erhöhen Sie die Wahrscheinlichkeit, dass potenzielle Partner und Kunden Ihr Programm über die organische Suche finden.
Verwaltung und Kontrolle der Web-Spider-Aktivität
Website-Betreiber haben verschiedene Werkzeuge zur Verfügung, um zu steuern, wie Web-Spider mit ihren Seiten interagieren. Die robots.txt-Datei ist der wichtigste Mechanismus zur Kommunikation von Crawler-Präferenzen und ermöglicht es, festzulegen, welche Seiten gecrawlt und welche ausgespart werden sollen. Das noindex-Meta-Tag bietet zusätzliche Kontrolle, indem es verhindert, dass bestimmte Seiten indexiert werden, auch wenn sie gecrawlt werden. Für Seiten, die gecrawlt, aber nicht indexiert werden sollen, kann das nofollow-Attribut auf Links verwendet werden, damit Spider diesen spezifischen Verbindungen nicht folgen. Website-Betreiber können außerdem die Google Search Console und andere Webmaster-Tools nutzen, um die Crawler-Aktivität zu überwachen und Probleme zu erkennen, die eine ordnungsgemäße Indexierung verhindern könnten. Es ist jedoch wichtig zu beachten, dass diese Tools zwar bei der Verwaltung legitimer Suchmaschinen-Spider helfen, bösartige Bots und Scraper diese Vorgaben aber oft ignorieren. Deshalb setzen viele Websites zusätzliche Sicherheitsmaßnahmen und Bot-Management-Systeme ein, um sich vor schädlicher Crawler-Aktivität zu schützen und gleichzeitig nützlichen Spidern den Zugang zu ermöglichen.
Die Unterscheidung zwischen Spidern und Scrapers
Obwohl Web-Spider und Web-Scraper beide automatisch Daten von Websites sammeln, verfolgen sie sehr unterschiedliche Zwecke und unterliegen unterschiedlichen ethischen Richtlinien. Web-Spider – insbesondere die von Suchmaschinen – befolgen das robots.txt-Protokoll und respektieren die Präferenzen von Website-Betreibern bezüglich des Crawlings. Scraper hingegen ignorieren diese Vorgaben oft und kopieren ganze Seiteninhalte, um sie andernorts erneut zu veröffentlichen – was Urheberrechtsverletzungen und Diebstahl geistigen Eigentums bedeuten kann. Spider sammeln und organisieren typischerweise nur Metadaten über Seiten, während Scraper den gesamten sichtbaren Inhalt kopieren. Suchmaschinen-Spider gelten im Allgemeinen als nützlich, da sie die Sichtbarkeit von Websites erhöhen, während Scraper meist als schädlich angesehen werden, da sie Inhalte stehlen und die Website-Performance beeinträchtigen können. Diese Unterscheidung ist wichtig für Website-Betreiber, die legitimen Crawler-Traffic von schädlicher Bot-Aktivität unterscheiden müssen. PostAffiliatePro hilft Affiliate-Managern, den Traffic auf ihren Affiliate-Seiten zu überwachen und zu verwalten, sodass legitime Spider auf Ihre Inhalte zugreifen können und gleichzeitig bösartige Scraping-Aktivitäten verhindert werden.
Maximieren Sie die Sichtbarkeit Ihres Affiliate-Netzwerks
Genau wie Web-Spider Ihre Inhalte entdecken und indexieren, hilft Ihnen PostAffiliatePro, Ihr gesamtes Affiliate-Netzwerk zu entdecken und zu verwalten. Verfolgen Sie jede Crawler-Interaktion und optimieren Sie die Leistung Ihres Affiliate-Programms mit unserer führenden Plattform.
Warum werden Webcrawler Spinnen genannt? Verständnis der Web-Indexierungstechnologie
Erfahren Sie, warum Webcrawler Spinnen genannt werden, wie sie funktionieren und welche entscheidende Rolle sie bei der Indexierung von Suchmaschinen spielen. E...