Crawler und ihre Rolle beim Suchmaschinen-Ranking
Crawler sammeln Daten und Informationen aus dem Internet, indem sie Websites besuchen und die Seiten lesen. Erfahren Sie mehr über sie.
5 Min. Lesezeit
SEO
Crawlers
+4
Erfahren Sie, wie Suchmaschinen-Crawler anhand von User-Agent-Strings, IP-Adressen, Anfrage-Mustern und Verhaltensanalysen erkannt werden können. Ein unverzichtbarer Leitfaden für Webmaster und Entwickler.
Suchmaschinen-Crawler können durch vier Hauptmethoden identifiziert werden: Analyse des User-Agent-Strings in den HTTP-Headern, Überprüfung der Quell-IP-Adresse und des Reverse-DNS-Hostnamens, Überwachung der Anfrage-Muster auf hochfrequente Zugriffe sowie Untersuchung von Verhaltensmerkmalen wie der Fähigkeit zur Ausführung von JavaScript.
Suchmaschinen-Crawler sind automatisierte Programme, die das Internet systematisch durchsuchen, um Webinhalte zu entdecken, zu analysieren und zu indexieren. Die Identifikation dieser Crawler ist für Webmaster, Entwickler und Affiliate-Marketer entscheidend, die ihre Website-Trafficmuster verstehen und legitimen Suchmaschinenzugriff sicherstellen müssen. Im Gegensatz zu bösartigen Bots, die versuchen, Daten abzugreifen oder Angriffe zu starten, identifizieren sich legitime Suchmaschinen-Crawler wie Googlebot, Bingbot und andere durch spezifische technische Merkmale, die überprüft und authentifiziert werden können.
Die Fähigkeit, zwischen legitimen Suchmaschinen-Crawlern und anderen Arten von Bots zu unterscheiden, ist im Jahr 2025 immer wichtiger geworden, da der Webtraffic weiter zunimmt und Bot-Aktivitäten immer ausgefeilter werden. Das Verständnis der Identifikationsmethoden hilft Ihnen, die Crawlability Ihrer Website zu optimieren, Ressourcen vor unbefugtem Zugriff zu schützen und sicherzustellen, dass Ihre Affiliate-Tracking-Systeme organischen Suchtraffic und andere Quellen korrekt unterscheiden. PostAffiliatePro bietet fortschrittliche Analysemöglichkeiten, mit denen Sie Traffic-Quellen präzise überwachen und kategorisieren, sodass Ihr Affiliate-Programm genaue Leistungsdaten erfasst.
Die einfachste Methode zur Identifikation von Suchmaschinen-Crawlern ist die Untersuchung des User-Agent-Strings im HTTP-Request-Header. Jede HTTP-Anfrage enthält einen User-Agent-Header, der den Client identifiziert, der die Anfrage stellt – sei es ein Webbrowser, eine Mobile App oder ein Crawler. Legitime Suchmaschinen-Crawler enthalten eindeutige Kennungen in ihren User-Agent-Strings, die Herkunft und Zweck klar ausweisen. Beispielsweise identifiziert sich der Google-Crawler als “Googlebot/2.1 (+http://www.google.com/bot.html)”, während Microsofts Bing-Crawler “Bingbot/2.0 (+http://www.bing.com/bingbot.htm)” verwendet.
Bei der Analyse von User-Agent-Strings sollten Sie auf spezifische Muster und Schlüsselwörter achten, die auf legitime Suchmaschinen-Crawler hinweisen. Der User-Agent-String enthält typischerweise den Namen des Crawlers, die Versionsnummer und einen Link zur Dokumentation oder Informationsseite des Crawlers. Legitime Crawler großer Suchmaschinen wie Google, Bing, Yahoo und Yandex folgen konsistenten Namenskonventionen und enthalten überprüfbare Informationen über ihren Zweck. Sie können diese User-Agent-Strings in Ihren Server-Access-Logs protokollieren und mit bekannten Crawler-Kennungen vergleichen, die von Suchmaschinen und Sicherheitsorganisationen gepflegt werden.
| Crawler-Name | Beispiel für User-Agent-String | Suchmaschine |
|---|---|---|
| Googlebot | Googlebot/2.1 (+http://www.google.com/bot.html) | |
| Bingbot | Bingbot/2.0 (+http://www.bing.com/bingbot.htm) | Microsoft Bing |
| Slurp | Slurp/cat (+http://help.yahoo.com/help/us/ysearch/slurp) | Yahoo |
| Yandexbot | Mozilla/5.0 (compatible; YandexBot/3.0) | Yandex |
| DuckDuckBot | DuckDuckBot/1.0 (+http://duckduckgo.com/duckduckbot.html) | DuckDuckGo |
Das alleinige Verlassen auf User-Agent-Strings zur Crawler-Identifikation hat jedoch Einschränkungen. Bösartige Bots können User-Agent-Strings vortäuschen, um legitime Crawler zu imitieren. Daher ist es wichtig, diese Methode mit weiteren Überprüfungstechniken zu kombinieren. Zudem verwenden einige legitime Crawler in bestimmten Situationen generische oder modifizierte User-Agent-Strings, sodass die Querverweise mit anderen Methoden zuverlässigere Ergebnisse liefern.
Richten Sie erweitertes Tracking in wenigen Minuten ein. Keine Kreditkarte erforderlich.
Die zweite wichtige Methode zur Identifikation von Suchmaschinen-Crawlern ist die Überprüfung der Quell-IP-Adresse und die Durchführung eines Reverse-DNS-Lookups. Wenn ein Crawler eine Anfrage an Ihren Server stellt, stammt diese von einer bestimmten IP-Adresse, die protokolliert und analysiert werden kann. Suchmaschinen veröffentlichen die IP-Adressbereiche, die von ihren Crawlern verwendet werden, sodass Webmaster prüfen können, ob eine Anfrage tatsächlich von der Infrastruktur der jeweiligen Suchmaschine stammt. Google beispielsweise pflegt eine umfassende Liste der von Googlebot und anderen Google-Crawlern verwendeten IP-Adressen.
Reverse-DNS-Lookup ist eine besonders effektive Verifizierungsmethode, bei der das DNS-System abgefragt wird, um den Hostnamen einer IP-Adresse zu bestimmen. Wenn Sie einen Reverse-DNS-Lookup für eine IP-Adresse durchführen, die angeblich von Google stammt, sollte diese auf einen Hostnamen innerhalb der Google-Domain aufgelöst werden (z. B. “crawl-66-249-64-1.googlebot.com”). Dieser Hostname kann anschließend durch einen Forward-DNS-Lookup überprüft werden, um sicherzustellen, dass der Hostname wieder auf die gleiche IP-Adresse verweist. Diese bidirektionale Verifizierungskette macht es für bösartige Akteure äußerst schwierig, die Identität eines Crawlers zu fälschen, da sie sowohl die IP-Adresse als auch die zugehörigen DNS-Einträge kontrollieren müssten.
Die offizielle Dokumentation von Google empfiehlt diese Verifizierungsmethode als den zuverlässigsten Weg, Googlebot-Anfragen zu bestätigen. Der Prozess beinhaltet die Überprüfung, dass der Reverse-DNS-Hostname dem Google-Domain-Muster entspricht, und anschließend die Bestätigung durch Forward-DNS-Lookup. Diese Methode ist besonders wertvoll für stark frequentierte Websites und Affiliate-Netzwerke, die eine genaue Traffic-Zuordnung sicherstellen und verhindern müssen, dass betrügerische Bot-Aktivitäten als legitimer Suchmaschinentraffic gezählt werden.
Die Analyse von Anfragemustern liefert wertvolle Einblicke in das Verhalten von Crawlern, indem untersucht wird, wie Anfragen über die Zeit und die Ressourcen Ihrer Website verteilt sind. Legitime Suchmaschinen-Crawler folgen vorhersehbaren Mustern, die sich deutlich vom menschlichen Surfverhalten oder von bösartigen Bots unterscheiden. Crawler senden Anfragen in der Regel in konstanten Intervallen, folgen einer logischen Traversierung durch die URL-Struktur Ihrer Website und beachten die Vorgaben Ihrer robots.txt-Datei. Durch die Überwachung dieser Muster können Sie legitime Crawler identifizieren und sie von verdächtigen Aktivitäten unterscheiden.
Bei der Analyse von Anfragemustern sollten Sie auf mehrere Schlüsselfaktoren achten, die auf legitimes Crawlerverhalten hinweisen. Prüfen Sie zunächst die Abfragehäufigkeit und -verteilung – legitime Crawler takten ihre Anfragen typischerweise, um Ihren Server nicht zu überlasten, und nutzen oft Algorithmen wie exponentielles Backoff, die bei HTTP-500-Fehlern oder anderen Serverstress-Anzeichen die Anfragefrequenz reduzieren. Analysieren Sie außerdem das URL-Traversierungsmuster – legitime Crawler folgen systematisch Links und berücksichtigen die Seitenstruktur, während bösartige Bots häufig zufällige oder sequentielle Anfragen an nicht existierende oder nicht verlinkte URLs stellen. Überwachen Sie zudem die angeforderten Ressourcentypen – legitime Crawler fordern in der Regel HTML-Seiten, CSS- und JavaScript-Dateien an, die für das Rendern von Seiten notwendig sind, und vermeiden unnötige Anfragen an Binärdateien oder sensible Verzeichnisse.
Sie können die Überwachung von Anfragemustern implementieren, indem Sie Ihre Server-Logs analysieren und Cluster von Anfragen mit gemeinsamen Merkmalen identifizieren. Tools wie Webanalyse-Plattformen und Server-Log-Analysetools können diesen Prozess automatisieren, indem sie ungewöhnliche Muster markieren. Wenn beispielsweise eine einzelne IP-Adresse 1.000 Anfragen pro Minute in einem sequentiellen Muster an verschiedene Produktseiten stellt, handelt es sich wahrscheinlich um einen Crawler. Legitime Suchmaschinen-Crawler senden hingegen Anfragen mit deutlich geringerer Frequenz und mit mehreren Sekunden Abstand, um Serverressourcen zu schonen und Rate-Limiting-Mechanismen nicht auszulösen.
Erfahren Sie als Erster von neuen Funktionen und Produkt-Updates.
Die Verhaltensanalyse untersucht, wie Crawler mit den Inhalten und der Technologie Ihrer Website interagieren, und liefert so Hinweise, um legitime Suchmaschinen-Crawler von anderen Bots zu unterscheiden. Eines der wichtigsten Verhaltensmerkmale ist die Fähigkeit zur Ausführung von JavaScript. Moderne Suchmaschinen wie Google rendern Seiten mit einem Headless-Browser (ähnlich wie Chrome), um JavaScript auszuführen und dynamisch generierte Inhalte zu erfassen. Das bedeutet, dass legitime Crawler JavaScript-Code auf Ihren Seiten ausführen, während viele bösartige Bots oder einfache Scraper dazu nicht in der Lage sind oder dies nicht tun.
Sie können die JavaScript-Ausführung erkennen, indem Sie Tracking-Code einbinden, der nur dann ausgeführt wird, wenn JavaScript aktiviert und funktionsfähig ist. Wenn eine Anfrage Ihre Seite aufruft, aber kein JavaScript-abhängiges Tracking auslöst oder keine dynamisch generierten Inhalte lädt, deutet dies darauf hin, dass es sich nicht um einen modernen Suchmaschinen-Crawler handelt. Zudem laden legitime Crawler normalerweise alle Ressourcen, die zum vollständigen Rendern einer Seite benötigt werden, einschließlich Bilder, Stylesheets und JavaScript-Dateien, während einfache Bots meist nur die HTML-Datei anfordern, ohne unterstützende Ressourcen zu laden.
Ein weiteres wichtiges Verhaltensmerkmal ist der Umgang mit interaktiven Elementen und Formularen. Legitime Suchmaschinen-Crawler senden keine Formulare ab, klicken keine Buttons und interagieren nicht mit dynamischen Inhalten auf eine Weise, die unerwünschte Nebeneffekte wie Bestellungen oder Datenänderungen auslösen würde. Ihr Fokus liegt auf dem Lesen und Analysieren von Inhalten, nicht auf der Interaktion damit. Bösartige Bots hingegen versuchen häufig, Formulare auszufüllen, Daten zu übermitteln oder Aktionen auszulösen, die Ihrer Website schaden oder Informationen stehlen könnten. Durch die Überwachung dieser Verhaltensmuster können Sie Anfragen identifizieren, die unbefugte Interaktionen versuchen, und sie von legitimer Crawler-Aktivität unterscheiden.
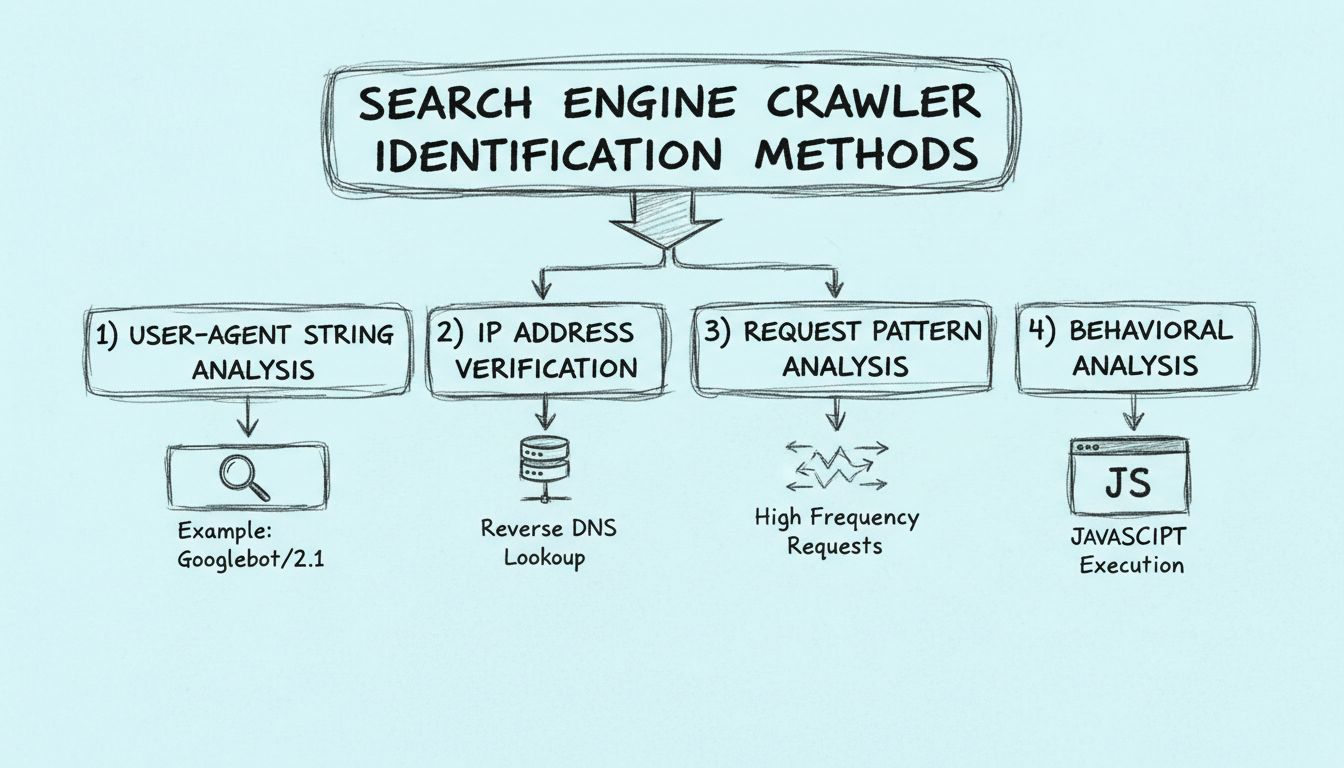
Der effektivste Ansatz zur Crawler-Identifikation kombiniert alle vier Methoden zu einem umfassenden Verifizierungsworkflow. Anstatt sich auf eine einzelne Identifikationsmethode zu verlassen, bietet ein gestaffeltes Überprüfungssystem einen robusten Schutz vor gefälschten Crawlern und gewährleistet eine genaue Traffic-Zuordnung. Beginnen Sie damit, User-Agent-String und IP-Adresse jeder Anfrage zu erfassen und vergleichen Sie diese mit bekannten Crawler-Datenbanken von Suchmaschinen und Sicherheitsorganisationen. Führen Sie anschließend einen Reverse-DNS-Lookup durch, um zu überprüfen, ob der Hostname der IP-Adresse mit der Domain der angegebenen Suchmaschine übereinstimmt. Abschließend analysieren Sie das Anfragemuster und die Verhaltensmerkmale, um sicherzustellen, dass die Aktivität mit dem Verhalten legitimer Crawler übereinstimmt.
Dieser mehrschichtige Ansatz ist besonders für Affiliate-Netzwerke und Performance-Marketing-Plattformen wie PostAffiliatePro wichtig, bei denen eine genaue Traffic-Zuordnung direkten Einfluss auf die Provisionsberechnung und die Programmintegrität hat. Durch die Implementierung einer umfassenden Crawler-Identifikation stellen Sie sicher, dass Ihre Affiliate-Tracking-Systeme legitimen Suchmaschinentraffic, bezahlten Werbetraffic und organischen User-Traffic korrekt unterscheiden. Diese Präzision ermöglicht bessere Leistungsanalysen, genauere ROI-Berechnungen und eine verbesserte Betrugserkennung.
Moderne Webinfrastrukturen erfordern ausgefeilte Systeme zur Crawler-Identifikation, die mit der Komplexität des heutigen Webtraffics umgehen können. Halten Sie zunächst eine aktuelle Liste legitimer Crawler-IP-Adressen und User-Agent-Strings vor, indem Sie offizielle Benachrichtigungen der großen Suchmaschinen abonnieren. Google, Bing und andere Suchmaschinen veröffentlichen Updates, wenn sie neue Crawler hinzufügen oder ihre Infrastruktur ändern. Bleiben Sie über diese Änderungen informiert, damit Ihre Identifikationssysteme stets aktuell bleiben. Implementieren Sie zudem serverseitiges Logging, das alle relevanten Anfrage-Metadaten wie User-Agent-Strings, IP-Adressen, Zeitstempel und angeforderte Ressourcen erfasst. Diese Daten bilden die Grundlage für Musteranalysen und Verhaltensüberwachung.
Erwägen Sie drittens die Implementierung einer Crawler-Überprüfungs-API oder eines Dienstes, der die Identität von Crawlern in Echtzeit automatisch überprüft. Viele Sicherheits- und Analyseplattformen bieten inzwischen Services zur Crawler-Identifikation an, die aktuelle Datenbanken legitimer Crawler pflegen und Anfragen daran abgleichen können. Viertens sollten Sie klare Richtlinien für den Umgang mit nicht identifizierten oder verdächtigen Crawler-Aktivitäten festlegen. Sie können diese Anfragen beispielsweise normal bedienen und für die Analyse protokollieren oder ein Rate Limiting einführen, um Ressourcenerschöpfung zu verhindern. Überprüfen und aktualisieren Sie abschließend regelmäßig Ihre Identifikationsregeln und Schwellenwerte anhand beobachteter Trafficmuster und neu auftretender Bedrohungen. Die Landschaft des Web-Crawlings entwickelt sich ständig weiter, und Ihre Identifikationssysteme sollten sich entsprechend anpassen, um wirksam zu bleiben.
Die Identifikation von Suchmaschinen-Crawlern erfordert ein umfassendes Verständnis verschiedener Verifizierungsmethoden und die Fähigkeit, diese zu einem effektiven Erkennungssystem zu kombinieren. Durch die Analyse von User-Agent-Strings, die Überprüfung von IP-Adressen mit Reverse-DNS-Lookups, die Überwachung von Anfragemustern und die Untersuchung von Verhaltensmerkmalen können Sie zuverlässig legitime Suchmaschinen-Crawler von anderen Bots und Traffic-Quellen unterscheiden. Diese Fähigkeit ist für Webmaster, Entwickler und Affiliate-Marketer unerlässlich, die ihre Traffic-Quellen verstehen und eine genaue Leistungsmessung sicherstellen müssen. Die fortschrittlichen Analyse- und Traffic-Überwachungsfunktionen von PostAffiliatePro helfen Ihnen, diese Identifikationsmethoden effektiv umzusetzen, damit Ihr Affiliate-Programm auch in einer zunehmend komplexen digitalen Landschaft zuverlässige Daten erfasst und die Integrität des Programms gewahrt bleibt.
PostAffiliatePro ist die führende Affiliate-Management-Software, mit der Sie Ihr Affiliate-Netzwerk präzise verfolgen, verwalten und optimieren können. Identifizieren Sie legitime Traffic-Quellen und maximieren Sie die Leistung Ihres Affiliate-Programms mit fortschrittlicher Analytik und Echtzeitüberwachung.
Crawler sammeln Daten und Informationen aus dem Internet, indem sie Websites besuchen und die Seiten lesen. Erfahren Sie mehr über sie.
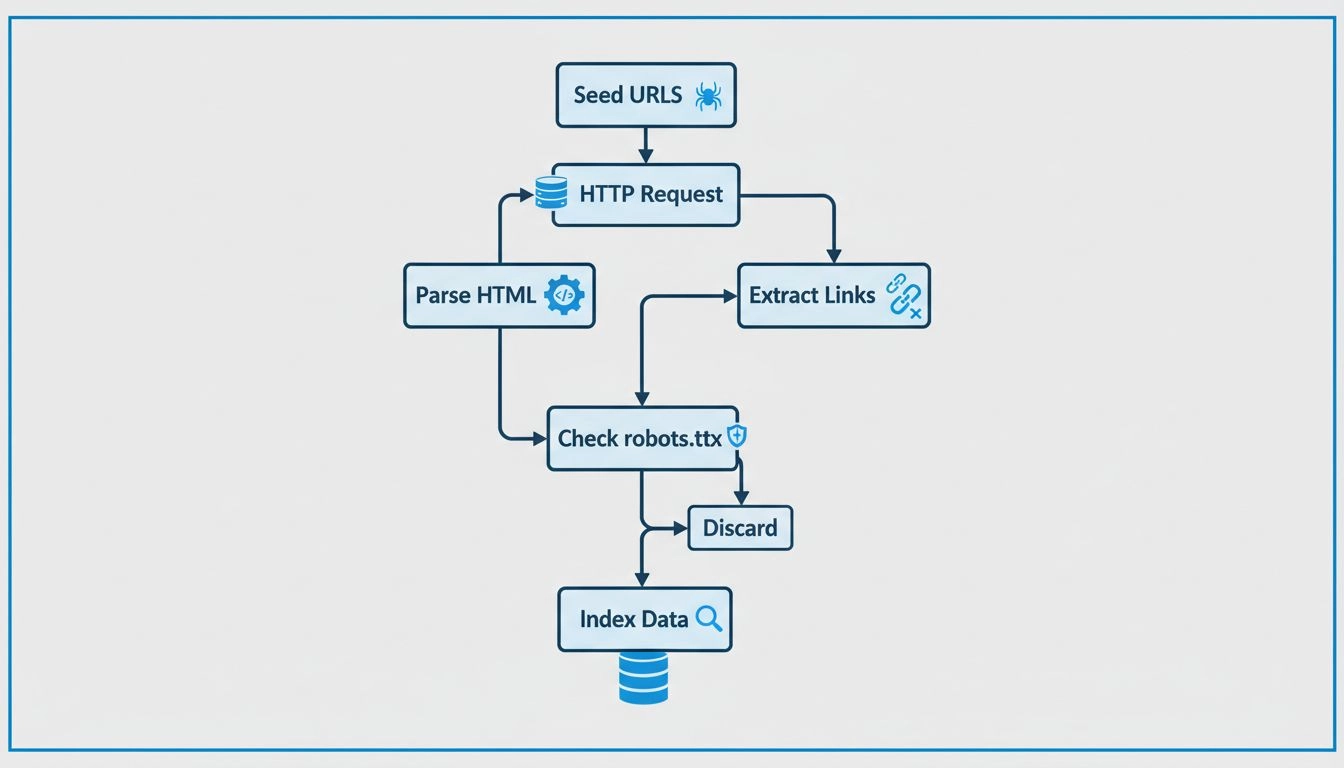
Erfahren Sie, wie Webcrawler arbeiten – von Seed-URLs bis zur Indexierung. Verstehen Sie den technischen Ablauf, Crawler-Typen, robots.txt-Regeln und wie Crawle...
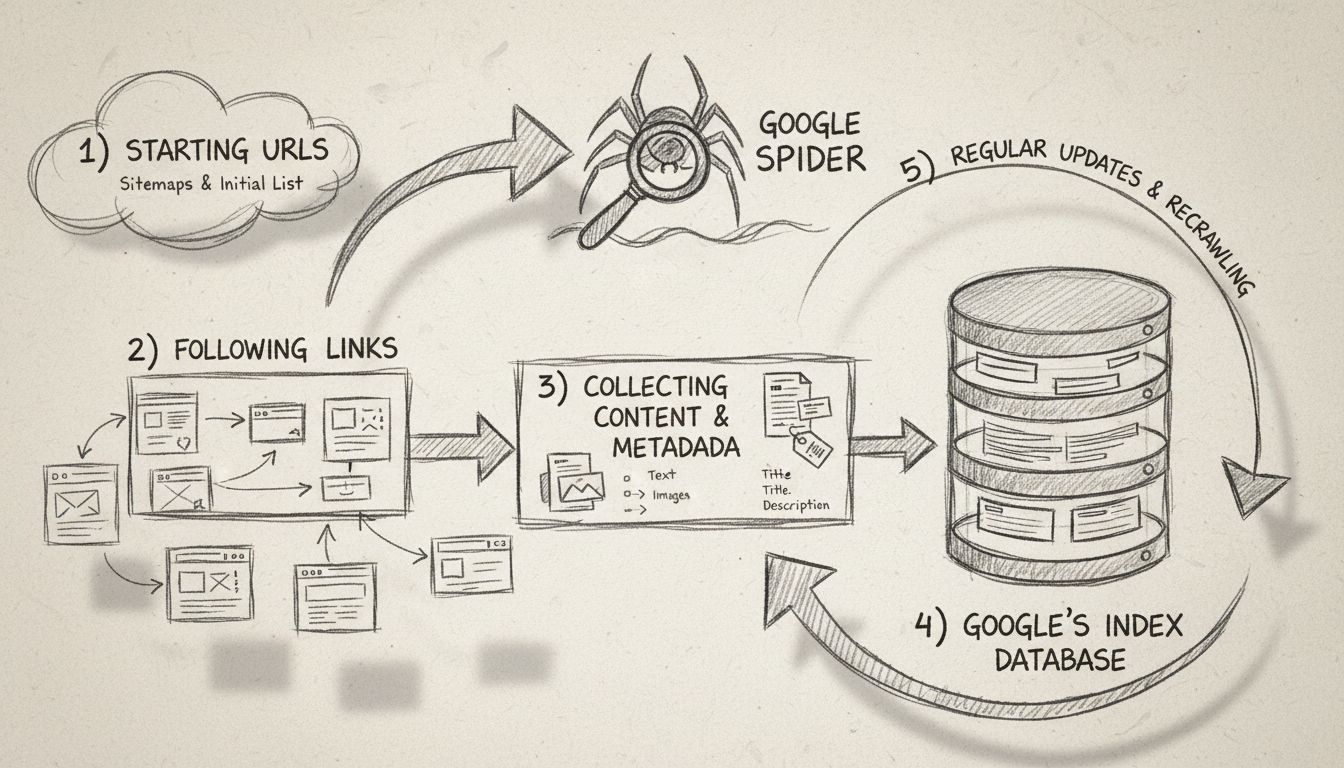
Erfahren Sie, was der Google Spider (Googlebot) ist, wie er Websites crawlt und indexiert und warum er für SEO unerlässlich ist. Entdecken Sie, wie Sie Ihre Web...
Treten Sie unserer Gemeinschaft zufriedener Kunden bei und bieten Sie exzellenten Kundensupport mit Post Affiliate Pro.